Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaive Bayes Classification for Subset Selection
Paper and Code
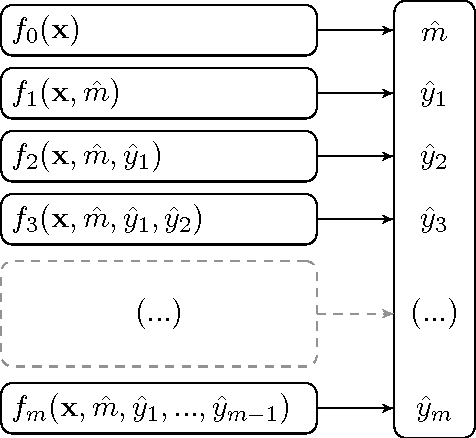


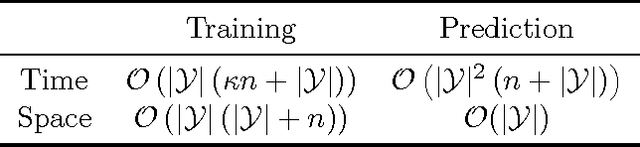
This article focuses on the question of learning how to automatically select a subset of items among a bigger set. We introduce a methodology for the inference of ensembles of discrete values, based on the Naive Bayes assumption. Our motivation stems from practical use cases where one wishes to predict an unordered set of (possibly interdependent) values from a set of observed features. This problem can be considered in the context of Multi-label Classification (MLC) where such values are seen as labels associated to continuous or discrete features. We introduce the \nbx algorithm, an extension of Naive Bayes classification into the multi-label domain, discuss its properties and evaluate our approach on real-world problems.
* 26 pages
View paper on