 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMy View is the Best View: Procedure Learning from Egocentric Videos
Paper and Code
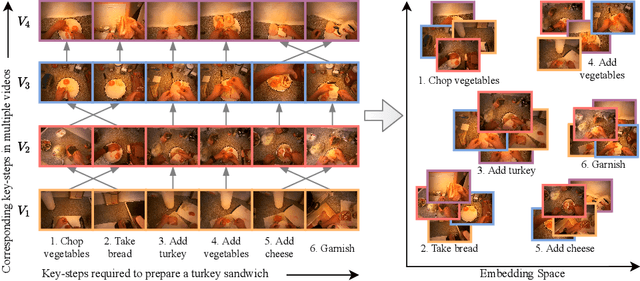


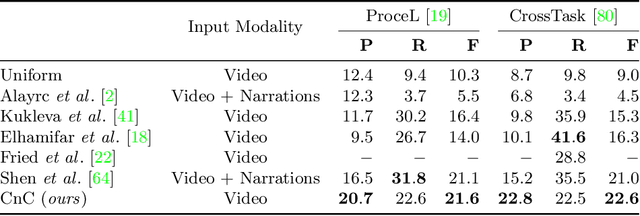
Procedure learning involves identifying the key-steps and determining their logical order to perform a task. Existing approaches commonly use third-person videos for learning the procedure, making the manipulated object small in appearance and often occluded by the actor, leading to significant errors. In contrast, we observe that videos obtained from first-person (egocentric) wearable cameras provide an unobstructed and clear view of the action. However, procedure learning from egocentric videos is challenging because (a) the camera view undergoes extreme changes due to the wearer's head motion, and (b) the presence of unrelated frames due to the unconstrained nature of the videos. Due to this, current state-of-the-art methods' assumptions that the actions occur at approximately the same time and are of the same duration, do not hold. Instead, we propose to use the signal provided by the temporal correspondences between key-steps across videos. To this end, we present a novel self-supervised Correspond and Cut (CnC) framework for procedure learning. CnC identifies and utilizes the temporal correspondences between the key-steps across multiple videos to learn the procedure. Our experiments show that CnC outperforms the state-of-the-art on the benchmark ProceL and CrossTask datasets by 5.2% and 6.3%, respectively. Furthermore, for procedure learning using egocentric videos, we propose the EgoProceL dataset consisting of 62 hours of videos captured by 130 subjects performing 16 tasks. The source code and the dataset are available on the project page https://sid2697.github.io/egoprocel/.