 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVP: Multi-Stage Vision-Language Pre-Training via Multi-Level Semantic Alignment
Paper and Code
Jan 29, 2022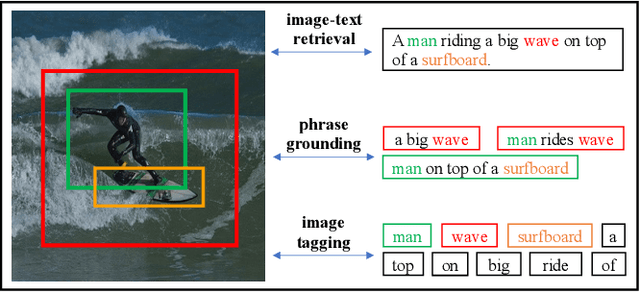
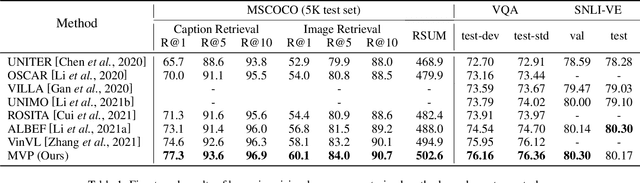
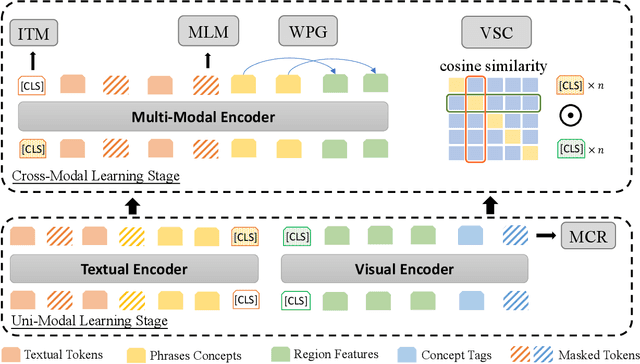
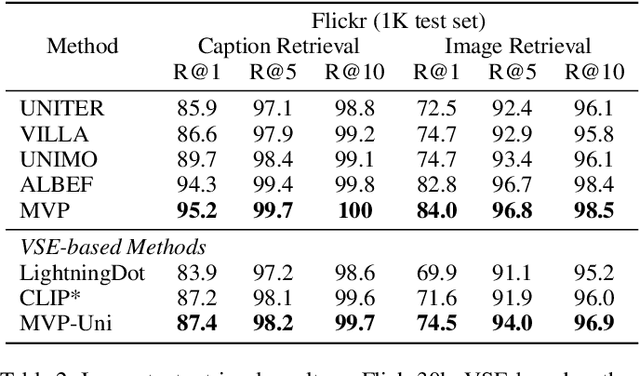
In this paper, we propose a Multi-stage Vision-language Pre-training (MVP) framework to learn cross-modality representation via multi-level semantic alignment. We introduce concepts in both modalities to construct two-level semantic representations for language and vision. Based on the multi-level input, we train the cross-modality model in two stages, namely, uni-modal learning and cross-modal learning. The former stage enforces within-modality interactions to learn multi-level semantics for each single modality. The latter stage enforces interactions across modalities via both coarse-grain and fine-grain semantic alignment tasks. Image-text matching and masked language modeling are then used to further optimize the pre-training model. Our model generates the-state-of-the-art results on several vision and language tasks.