 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Generative Transformer Learning for Cross-view Geo-localization
Paper and Code
Mar 17, 2022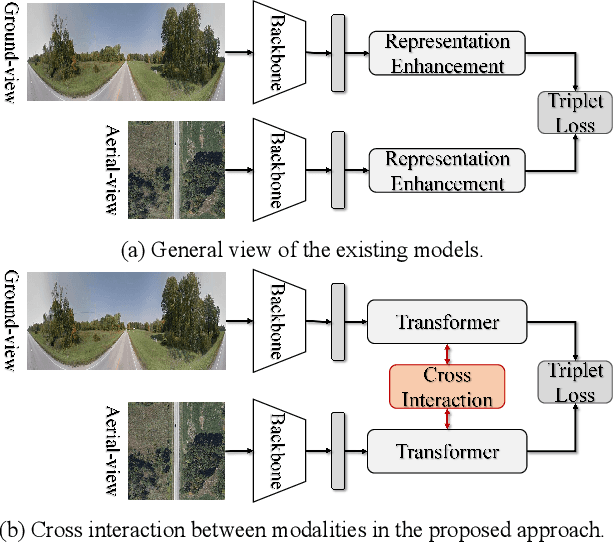
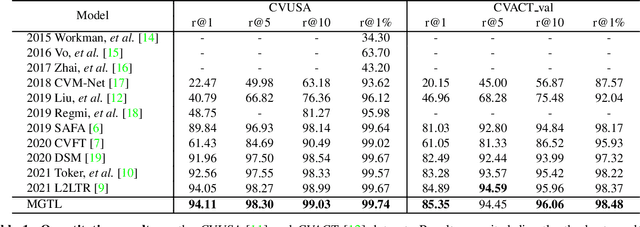
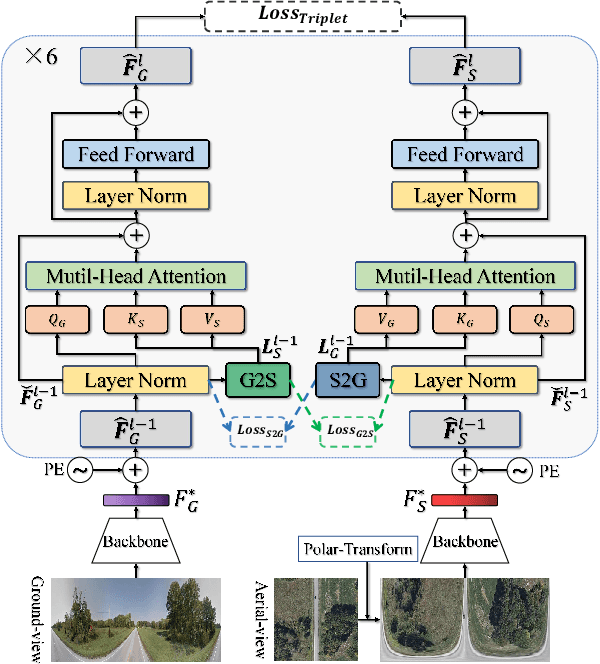

Cross-view geo-localization (CVGL), which aims to estimate the geographical location of the ground-level camera by matching against enormous geo-tagged aerial (e.g., satellite) images, remains extremely challenging due to the drastic appearance differences across views. Existing methods mainly employ Siamese-like CNNs to extract global descriptors without examining the mutual benefits between the two modes. In this paper, we present a novel approach using cross-modal knowledge generative tactics in combination with transformer, namely mutual generative transformer learning (MGTL), for CVGL. Specifically, MGTL develops two separate generative modules--one for aerial-like knowledge generation from ground-level semantic information and vice versa--and fully exploits their mutual benefits through the attention mechanism. Experiments on challenging public benchmarks, CVACT and CVUSA, demonstrate the effectiveness of the proposed method compared to the existing state-of-the-art models.