 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUTANT: A Multi-sentential Code-mixed Hinglish Dataset
Paper and Code

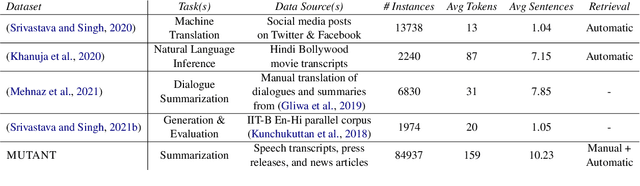
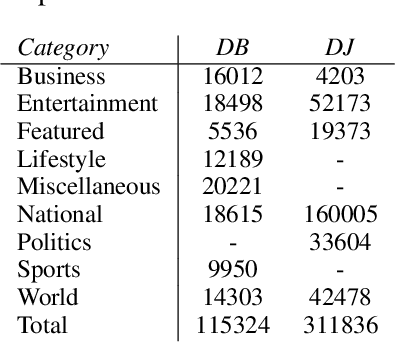
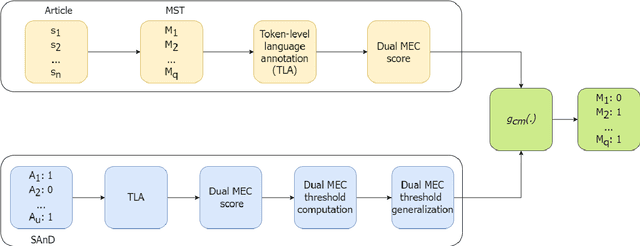
The multi-sentential long sequence textual data unfolds several interesting research directions pertaining to natural language processing and generation. Though we observe several high-quality long-sequence datasets for English and other monolingual languages, there is no significant effort in building such resources for code-mixed languages such as Hinglish (code-mixing of Hindi-English). In this paper, we propose a novel task of identifying multi-sentential code-mixed text (MCT) from multilingual articles. As a use case, we leverage multilingual articles from two different data sources and build a first-of-its-kind multi-sentential code-mixed Hinglish dataset i.e., MUTANT. We propose a token-level language-aware pipeline and extend the existing metrics measuring the degree of code-mixing to a multi-sentential framework and automatically identify MCT in the multilingual articles. The MUTANT dataset comprises 67k articles with 85k identified Hinglish MCTs. To facilitate future research, we make the publicly available.