 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask Training with Text Data for End-to-End Speech Recognition
Paper and Code
Oct 27, 2020


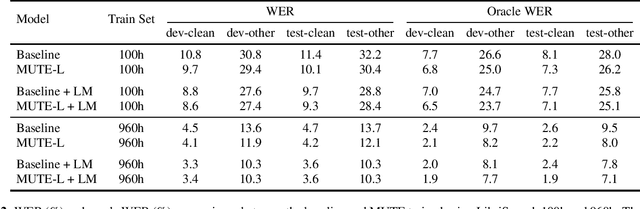
We propose a multitask training method for attention-based end-to-end speech recognition models to better incorporate language level information. We regularize the decoder in a sequence-to-sequence architecture by multitask training it on both the speech recognition task and a next-token prediction language modeling task. Trained on either the 100 hour subset of LibriSpeech or the full 960 hour dataset, the proposed method leads to an 11% relative performance improvement over the baseline and is comparable to language model shallow fusion, without requiring an additional neural network during decoding. Analyses of sample output sentences and the word error rate on rare words demonstrate that the proposed method can incorporate language level information effectively.