 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Geometric Methods for Data Sets II: Geometric Multi-Resolution Analysis
Paper and Code
Sep 08, 2011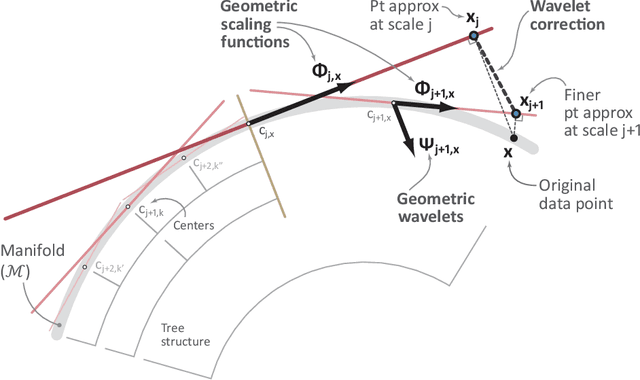



Data sets are often modeled as point clouds in $R^D$, for $D$ large. It is often assumed that the data has some interesting low-dimensional structure, for example that of a $d$-dimensional manifold $M$, with $d$ much smaller than $D$. When $M$ is simply a linear subspace, one may exploit this assumption for encoding efficiently the data by projecting onto a dictionary of $d$ vectors in $R^D$ (for example found by SVD), at a cost $(n+D)d$ for $n$ data points. When $M$ is nonlinear, there are no "explicit" constructions of dictionaries that achieve a similar efficiency: typically one uses either random dictionaries, or dictionaries obtained by black-box optimization. In this paper we construct data-dependent multi-scale dictionaries that aim at efficient encoding and manipulating of the data. Their construction is fast, and so are the algorithms that map data points to dictionary coefficients and vice versa. In addition, data points are guaranteed to have a sparse representation in terms of the dictionary. We think of dictionaries as the analogue of wavelets, but for approximating point clouds rather than functions.