 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiplicative Position-aware Transformer Models for Language Understanding
Paper and Code
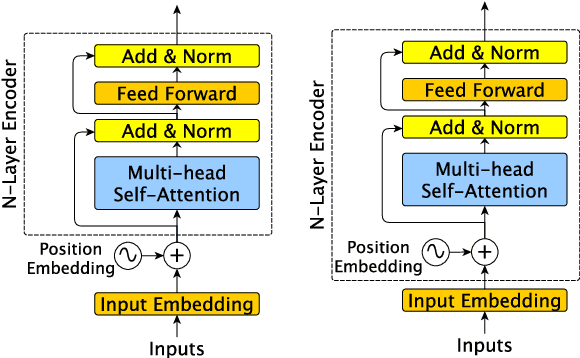

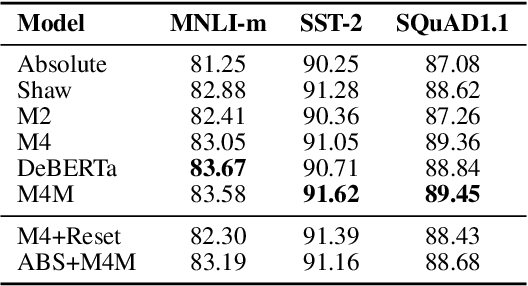
Transformer models, which leverage architectural improvements like self-attention, perform remarkably well on Natural Language Processing (NLP) tasks. The self-attention mechanism is position agnostic. In order to capture positional ordering information, various flavors of absolute and relative position embeddings have been proposed. However, there is no systematic analysis on their contributions and a comprehensive comparison of these methods is missing in the literature. In this paper, we review major existing position embedding methods and compare their accuracy on downstream NLP tasks, using our own implementations. We also propose a novel multiplicative embedding method which leads to superior accuracy when compared to existing methods. Finally, we show that our proposed embedding method, served as a drop-in replacement of the default absolute position embedding, can improve the RoBERTa-base and RoBERTa-large models on SQuAD1.1 and SQuAD2.0 datasets.