 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple-hypothesis CTC-based semi-supervised adaptation of end-to-end speech recognition
Paper and Code
Mar 31, 2021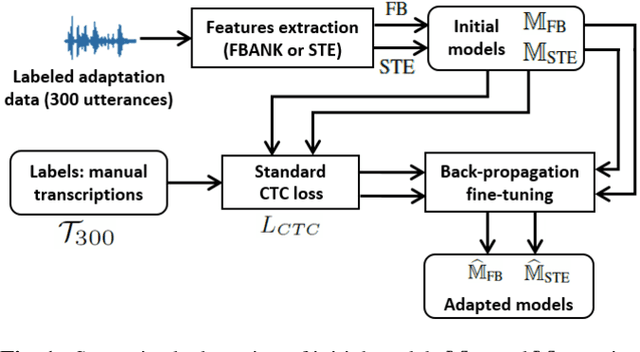
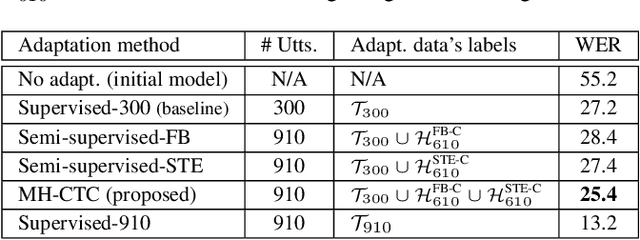
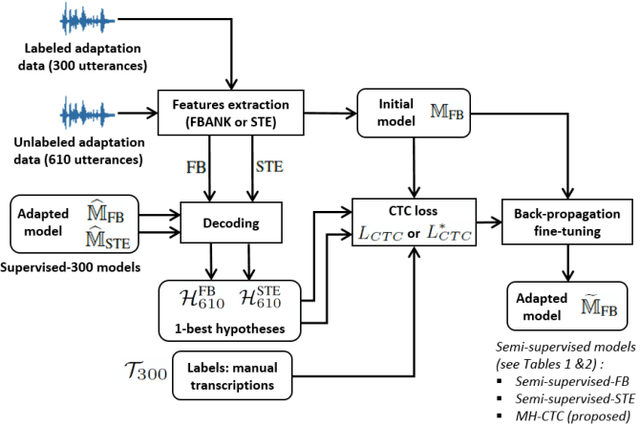
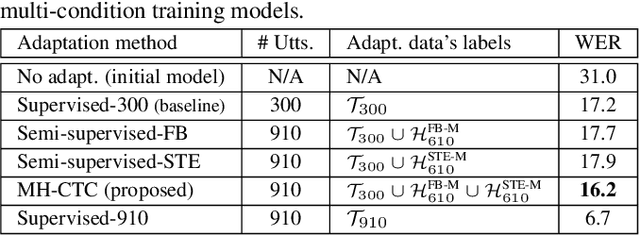
This paper proposes an adaptation method for end-to-end speech recognition. In this method, multiple automatic speech recognition (ASR) 1-best hypotheses are integrated in the computation of the connectionist temporal classification (CTC) loss function. The integration of multiple ASR hypotheses helps alleviating the impact of errors in the ASR hypotheses to the computation of the CTC loss when ASR hypotheses are used. When being applied in semi-supervised adaptation scenarios where part of the adaptation data do not have labels, the CTC loss of the proposed method is computed from different ASR 1-best hypotheses obtained by decoding the unlabeled adaptation data. Experiments are performed in clean and multi-condition training scenarios where the CTC-based end-to-end ASR systems are trained on Wall Street Journal (WSJ) clean training data and CHiME-4 multi-condition training data, respectively, and tested on Aurora-4 test data. The proposed adaptation method yields 6.6% and 5.8% relative word error rate (WER) reductions in clean and multi-condition training scenarios, respectively, compared to a baseline system which is adapted with part of the adaptation data having manual transcriptions using back-propagation fine-tuning.