 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodel Sensor Fusion for Learning Rich Models for Interacting Soft Robots
Paper and Code
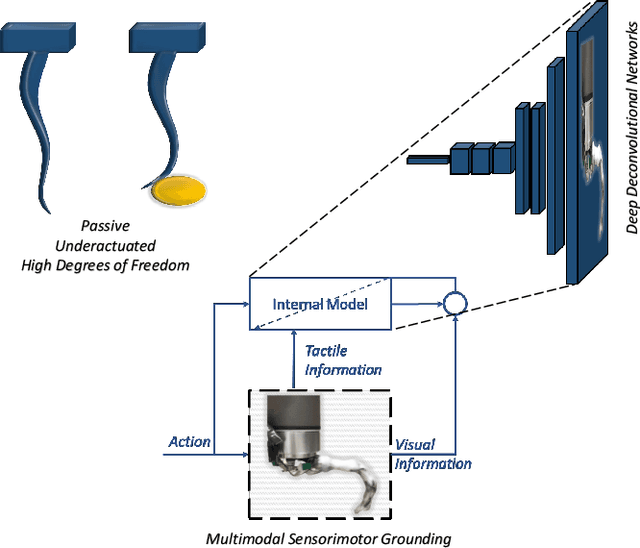
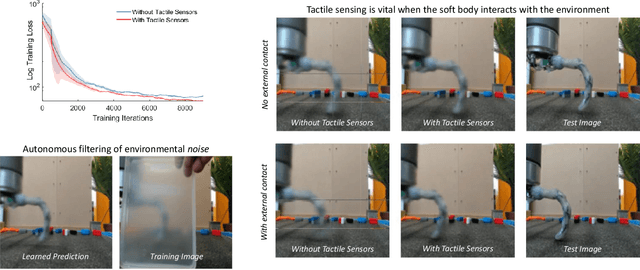
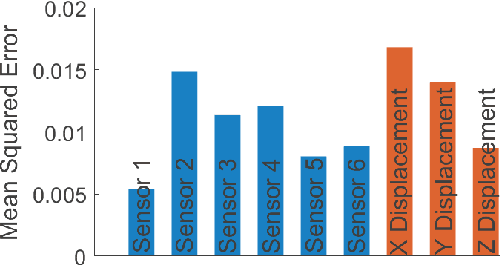
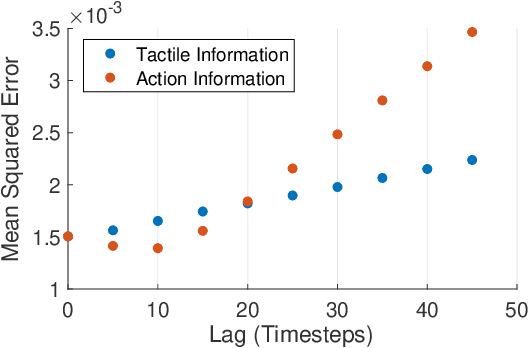
Soft robots are typically approximated as low-dimensional systems, especially when learning-based methods are used. This leads to models that are limited in their capability to predict the large number of deformation modes and interactions that a soft robot can have. In this work, we present a deep-learning methodology to learn high-dimensional visual models of a soft robot combining multimodal sensorimotor information. The models are learned in an end-to-end fashion, thereby requiring no intermediate sensor processing or grounding of data. The capabilities and advantages of such a modelling approach are shown on a soft anthropomorphic finger with embedded soft sensors. We also show that how such an approach can be extended to develop higher level cognitive functions like identification of the self and the external environment and acquiring object manipulation skills. This work is a step towards the integration of soft robotics and developmental robotics architectures to create the next generation of intelligent soft robots.