 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Representations Learning Based on Mutual Information Maximization and Minimization and Identity Embedding for Multimodal Sentiment Analysis
Paper and Code
Jan 10, 2022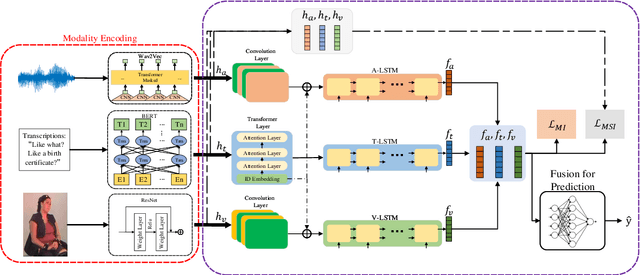
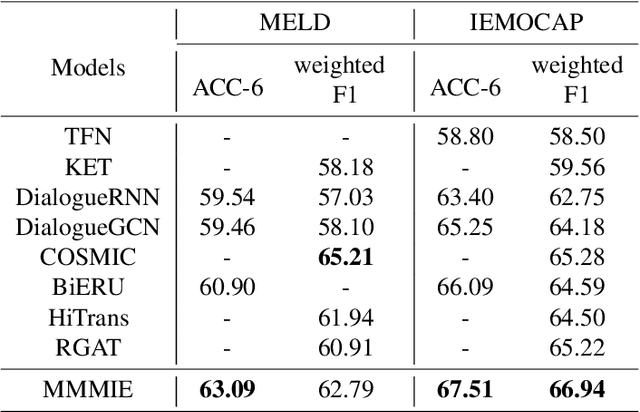
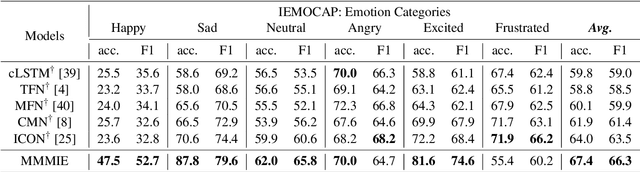
Multimodal sentiment analysis (MSA) is a fundamental complex research problem due to the heterogeneity gap between different modalities and the ambiguity of human emotional expression. Although there have been many successful attempts to construct multimodal representations for MSA, there are still two challenges to be addressed: 1) A more robust multimodal representation needs to be constructed to bridge the heterogeneity gap and cope with the complex multimodal interactions, and 2) the contextual dynamics must be modeled effectively throughout the information flow. In this work, we propose a multimodal representation model based on Mutual information Maximization and Minimization and Identity Embedding (MMMIE). We combine mutual information maximization between modal pairs, and mutual information minimization between input data and corresponding features to mine the modal-invariant and task-related information. Furthermore, Identity Embedding is proposed to prompt the downstream network to perceive the contextual information. Experimental results on two public datasets demonstrate the effectiveness of the proposed model.