 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Pre-Training Model for Sequence-based Prediction of Protein-Protein Interaction
Paper and Code
Dec 09, 2021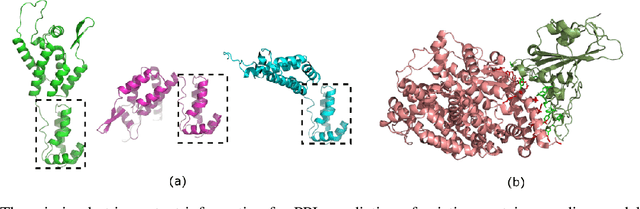
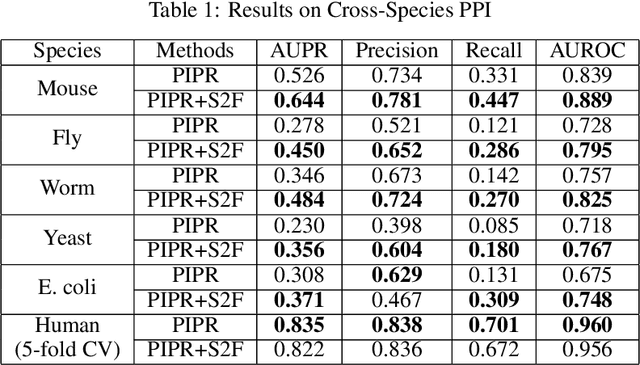


Protein-protein interactions (PPIs) are essentials for many biological processes where two or more proteins physically bind together to achieve their functions. Modeling PPIs is useful for many biomedical applications, such as vaccine design, antibody therapeutics, and peptide drug discovery. Pre-training a protein model to learn effective representation is critical for PPIs. Most pre-training models for PPIs are sequence-based, which naively adopt the language models used in natural language processing to amino acid sequences. More advanced works utilize the structure-aware pre-training technique, taking advantage of the contact maps of known protein structures. However, neither sequences nor contact maps can fully characterize structures and functions of the proteins, which are closely related to the PPI problem. Inspired by this insight, we propose a multimodal protein pre-training model with three modalities: sequence, structure, and function (S2F). Notably, instead of using contact maps to learn the amino acid-level rigid structures, we encode the structure feature with the topology complex of point clouds of heavy atoms. It allows our model to learn structural information about not only the backbones but also the side chains. Moreover, our model incorporates the knowledge from the functional description of proteins extracted from literature or manual annotations. Our experiments show that the S2F learns protein embeddings that achieve good performances on a variety of PPIs tasks, including cross-species PPI, antibody-antigen affinity prediction, antibody neutralization prediction for SARS-CoV-2, and mutation-driven binding affinity change prediction.