 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal perception for dexterous manipulation
Paper and Code
Dec 28, 2021


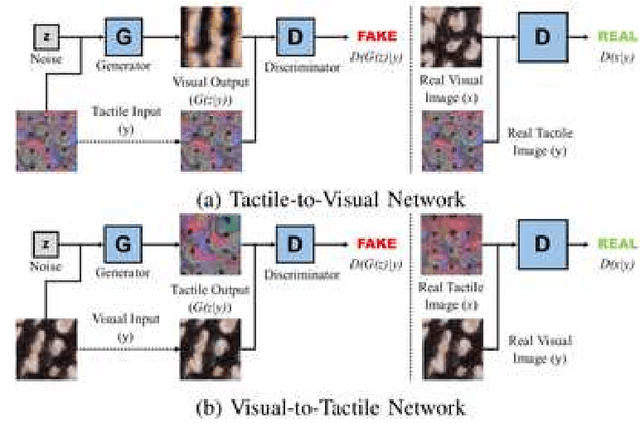
Humans usually perceive the world in a multimodal way that vision, touch, sound are utilised to understand surroundings from various dimensions. These senses are combined together to achieve a synergistic effect where the learning is more effectively than using each sense separately. For robotics, vision and touch are two key senses for the dexterous manipulation. Vision usually gives us apparent features like shape, color, and the touch provides local information such as friction, texture, etc. Due to the complementary properties between visual and tactile senses, it is desirable for us to combine vision and touch for a synergistic perception and manipulation. Many researches have been investigated about multimodal perception such as cross-modal learning, 3D reconstruction, multimodal translation with vision and touch. Specifically, we propose a cross-modal sensory data generation framework for the translation between vision and touch, which is able to generate realistic pseudo data. By using this cross-modal translation method, it is desirable for us to make up inaccessible data, helping us to learn the object's properties from different views. Recently, the attention mechanism becomes a popular method either in visual perception or in tactile perception. We propose a spatio-temporal attention model for tactile texture recognition, which takes both spatial features and time dimension into consideration. Our proposed method not only pays attention to the salient features in each spatial feature, but also models the temporal correlation in the through the time. The obvious improvement proves the efficiency of our selective attention mechanism. The spatio-temporal attention method has potential in many applications such as grasping, recognition, and multimodal perception.