 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Graph-based Transformer Framework for Biomedical Relation Extraction
Paper and Code
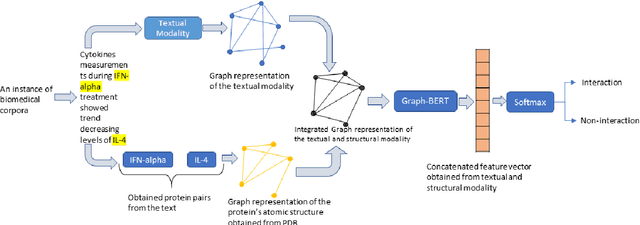
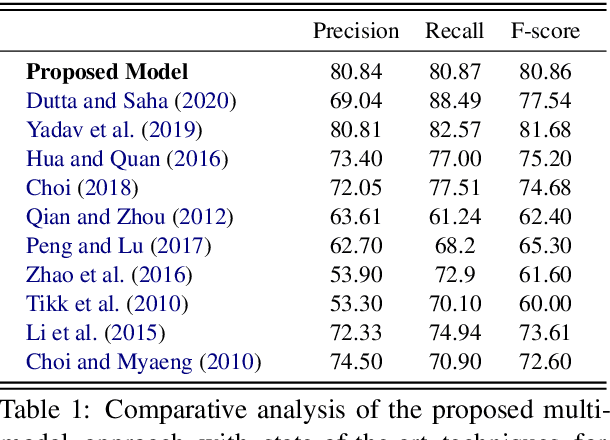
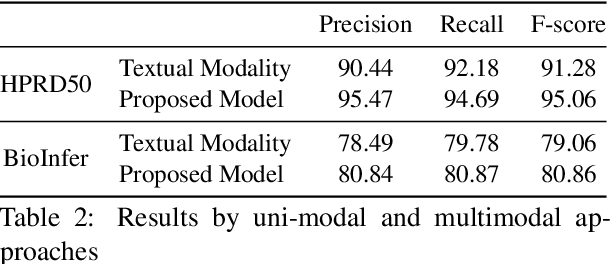
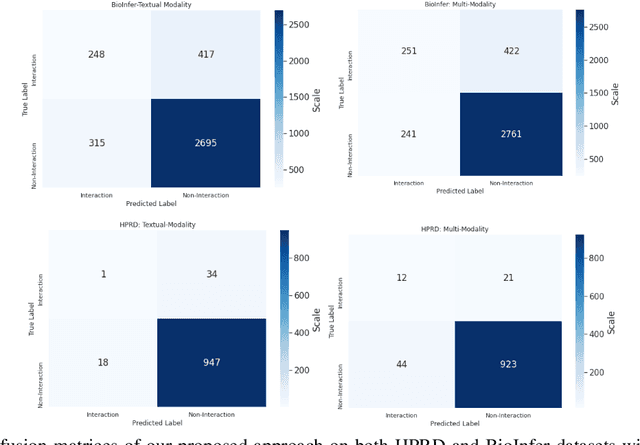
The recent advancement of pre-trained Transformer models has propelled the development of effective text mining models across various biomedical tasks. However, these models are primarily learned on the textual data and often lack the domain knowledge of the entities to capture the context beyond the sentence. In this study, we introduced a novel framework that enables the model to learn multi-omnics biological information about entities (proteins) with the help of additional multi-modal cues like molecular structure. Towards this, rather developing modality-specific architectures, we devise a generalized and optimized graph based multi-modal learning mechanism that utilizes the GraphBERT model to encode the textual and molecular structure information and exploit the underlying features of various modalities to enable end-to-end learning. We evaluated our proposed method on ProteinProtein Interaction task from the biomedical corpus, where our proposed generalized approach is observed to be benefited by the additional domain-specific modality.