 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Clustering with Role Induced Constraints for Speaker Diarization
Paper and Code
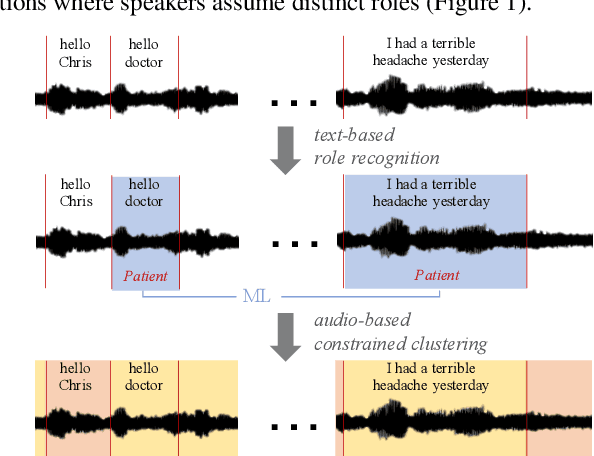
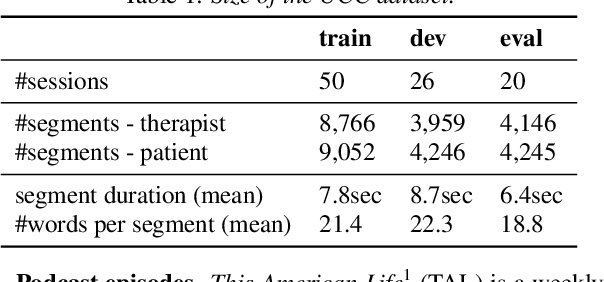
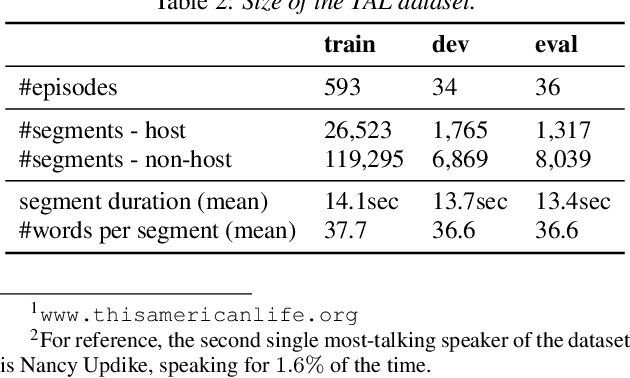
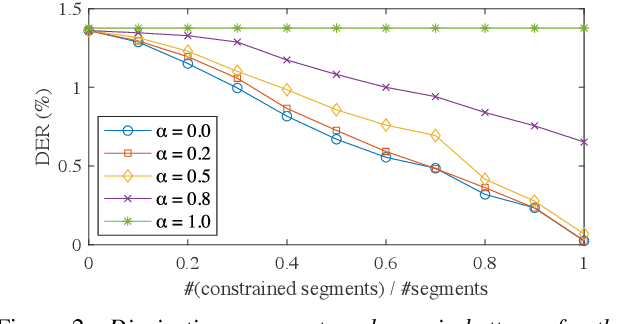
Speaker clustering is an essential step in conventional speaker diarization systems and is typically addressed as an audio-only speech processing task. The language used by the participants in a conversation, however, carries additional information that can help improve the clustering performance. This is especially true in conversational interactions, such as business meetings, interviews, and lectures, where specific roles assumed by interlocutors (manager, client, teacher, etc.) are often associated with distinguishable linguistic patterns. In this paper we propose to employ a supervised text-based model to extract speaker roles and then use this information to guide an audio-based spectral clustering step by imposing must-link and cannot-link constraints between segments. The proposed method is applied on two different domains, namely on medical interactions and on podcast episodes, and is shown to yield improved results when compared to the audio-only approach.