 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultichannel-based learning for audio object extraction
Paper and Code
Feb 11, 2021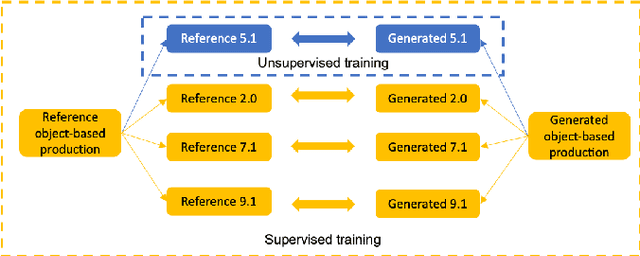
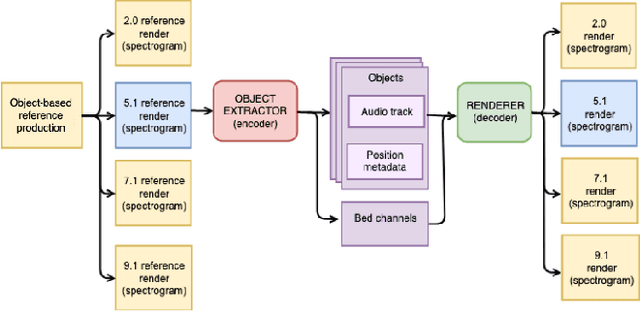
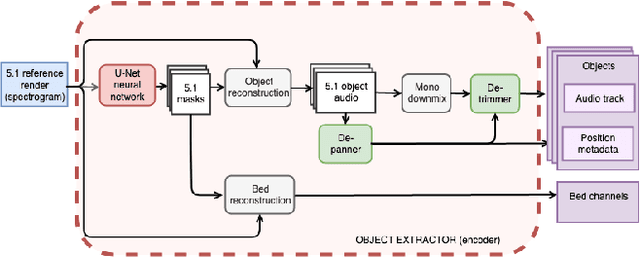
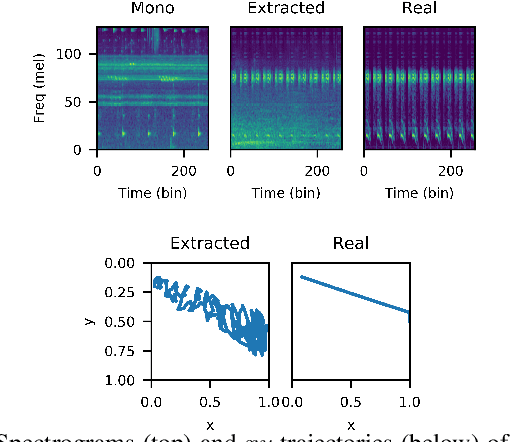
The current paradigm for creating and deploying immersive audio content is based on audio objects, which are composed of an audio track and position metadata. While rendering an object-based production into a multichannel mix is straightforward, the reverse process involves sound source separation and estimating the spatial trajectories of the extracted sources. Besides, cinematic object-based productions are often composed by dozens of simultaneous audio objects, which poses a scalability challenge for audio object extraction. Here, we propose a novel deep learning approach to object extraction that learns from the multichannel renders of object-based productions, instead of directly learning from the audio objects themselves. This approach allows tackling the object scalability challenge and also offers the possibility to formulate the problem in a supervised or an unsupervised fashion. Since, to our knowledge, no other works have previously addressed this topic, we first define the task and propose an evaluation methodology, and then discuss under what circumstances our methods outperform the proposed baselines.