 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Spatial-Temporal Network for Continuous Sign Language Recognition
Paper and Code
Apr 19, 2022
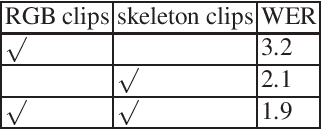
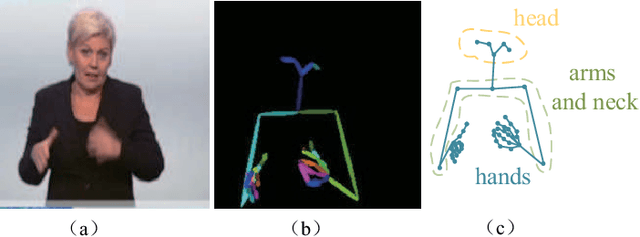

Sign language is a beautiful visual language and is also the primary language used by speaking and hearing-impaired people. However, sign language has many complex expressions, which are difficult for the public to understand and master. Sign language recognition algorithms will significantly facilitate communication between hearing-impaired people and normal people. Traditional continuous sign language recognition often uses a sequence learning method based on Convolutional Neural Network (CNN) and Long Short-Term Memory Network (LSTM). These methods can only learn spatial and temporal features separately, which cannot learn the complex spatial-temporal features of sign language. LSTM is also difficult to learn long-term dependencies. To alleviate these problems, this paper proposes a multi-view spatial-temporal continuous sign language recognition network. The network consists of three parts. The first part is a Multi-View Spatial-Temporal Feature Extractor Network (MSTN), which can directly extract the spatial-temporal features of RGB and skeleton data; the second is a sign language encoder network based on Transformer, which can learn long-term dependencies; the third is a Connectionist Temporal Classification (CTC) decoder network, which is used to predict the whole meaning of the continuous sign language. Our algorithm is tested on two public sign language datasets SLR-100 and PHOENIX-Weather 2014T (RWTH). As a result, our method achieves excellent performance on both datasets. The word error rate on the SLR-100 dataset is 1.9%, and the word error rate on the RWTHPHOENIX-Weather dataset is 22.8%.