 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Object Pose Refinement With Differentiable Renderer
Paper and Code
Jul 06, 2022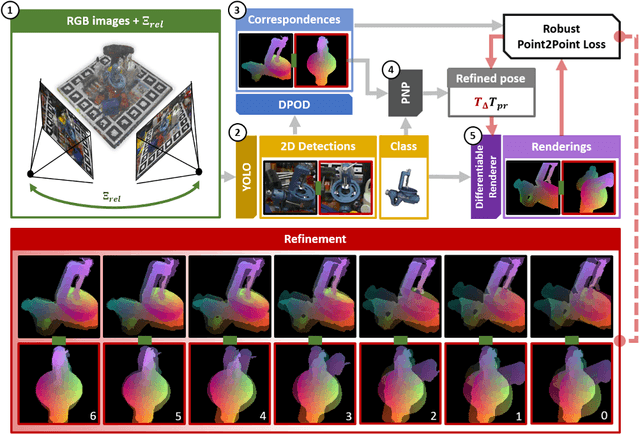

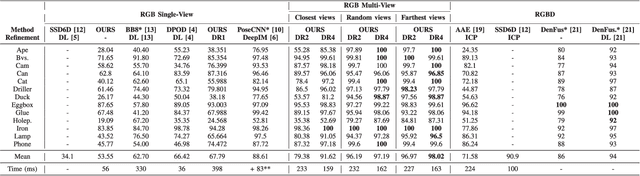
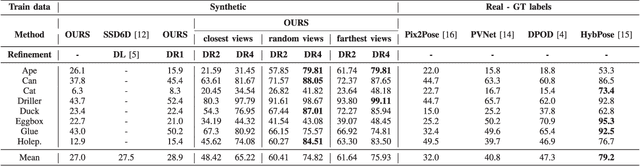
This paper introduces a novel multi-view 6 DoF object pose refinement approach focusing on improving methods trained on synthetic data. It is based on the DPOD detector, which produces dense 2D-3D correspondences between the model vertices and the image pixels in each frame. We have opted for the use of multiple frames with known relative camera transformations, as it allows introduction of geometrical constraints via an interpretable ICP-like loss function. The loss function is implemented with a differentiable renderer and is optimized iteratively. We also demonstrate that a full detection and refinement pipeline, which is trained solely on synthetic data, can be used for auto-labeling real data. We perform quantitative evaluation on LineMOD, Occlusion, Homebrewed and YCB-V datasets and report excellent performance in comparison to the state-of-the-art methods trained on the synthetic and real data. We demonstrate empirically that our approach requires only a few frames and is robust to close camera locations and noise in extrinsic camera calibration, making its practical usage easier and more ubiquitous.