 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view object pose estimation from correspondence distributions and epipolar geometry
Paper and Code
Oct 03, 2022

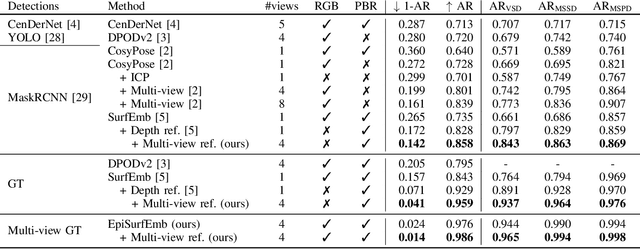
In many automation tasks involving manipulation of rigid objects, the poses of the objects must be acquired. Vision-based pose estimation using a single RGB or RGB-D sensor is especially popular due to its broad applicability. However, single-view pose estimation is inherently limited by depth ambiguity and ambiguities imposed by various phenomena like occlusion, self-occlusion, reflections, etc. Aggregation of information from multiple views can potentially resolve these ambiguities, but the current state-of-the-art multi-view pose estimation method only uses multiple views to aggregate single-view pose estimates, and thus rely on obtaining good single-view estimates. We present a multi-view pose estimation method which aggregates learned 2D-3D distributions from multiple views for both the initial estimate and optional refinement. Our method performs probabilistic sampling of 3D-3D correspondences under epipolar constraints using learned 2D-3D correspondence distributions which are implicitly trained to respect visual ambiguities such as symmetry. Evaluation on the T-LESS dataset shows that our method reduces pose estimation errors by 80-91% compared to the best single-view method, and we present state-of-the-art results on T-LESS with four views, even compared with methods using five and eight views.