 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Option Learning and Discovery for Stochastic Path Planning
Paper and Code
Sep 30, 2022

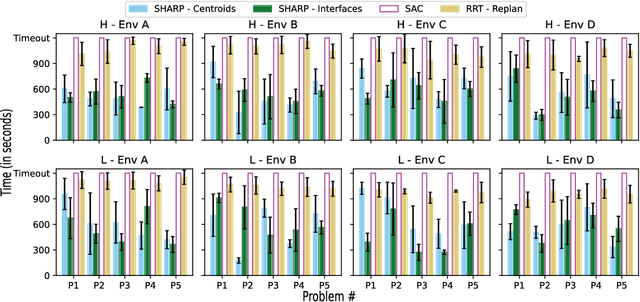
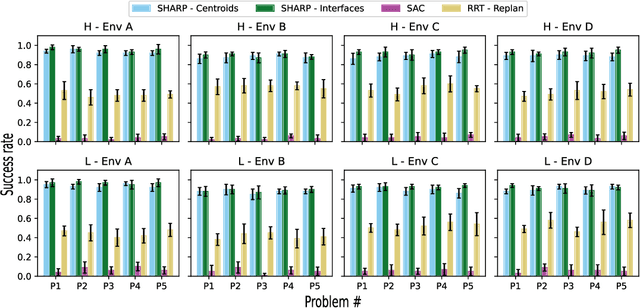
This paper addresses the problem of reliably and efficiently solving broad classes of long-horizon stochastic path planning problems. Starting with a vanilla RL formulation with a stochastic dynamics simulator and an occupancy matrix of the environment, our approach computes useful options with policies as well as high-level paths that compose the discovered options. Our main contributions are (1) data-driven methods for creating abstract states that serve as endpoints for helpful options, (2) methods for computing option policies using auto-generated option guides in the form of dense pseudo-reward functions, and (3) an overarching algorithm for composing the computed options. We show that this approach yields strong guarantees of executability and solvability: under fairly general conditions, the computed option guides lead to composable option policies and consequently ensure downward refinability. Empirical evaluation on a range of robots, environments, and tasks shows that this approach effectively transfers knowledge across related tasks and that it outperforms existing approaches by a significant margin.