 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning with Group-Specific Feature Space Sharing
Paper and Code
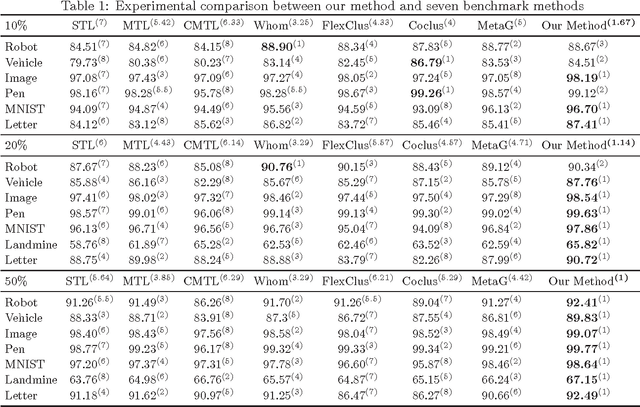

When faced with learning a set of inter-related tasks from a limited amount of usable data, learning each task independently may lead to poor generalization performance. Multi-Task Learning (MTL) exploits the latent relations between tasks and overcomes data scarcity limitations by co-learning all these tasks simultaneously to offer improved performance. We propose a novel Multi-Task Multiple Kernel Learning framework based on Support Vector Machines for binary classification tasks. By considering pair-wise task affinity in terms of similarity between a pair's respective feature spaces, the new framework, compared to other similar MTL approaches, offers a high degree of flexibility in determining how similar feature spaces should be, as well as which pairs of tasks should share a common feature space in order to benefit overall performance. The associated optimization problem is solved via a block coordinate descent, which employs a consensus-form Alternating Direction Method of Multipliers algorithm to optimize the Multiple Kernel Learning weights and, hence, to determine task affinities. Empirical evaluation on seven data sets exhibits a statistically significant improvement of our framework's results compared to the ones of several other Clustered Multi-Task Learning methods.