 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal unsupervised brain image registration using edge maps
Paper and Code
Feb 22, 2022
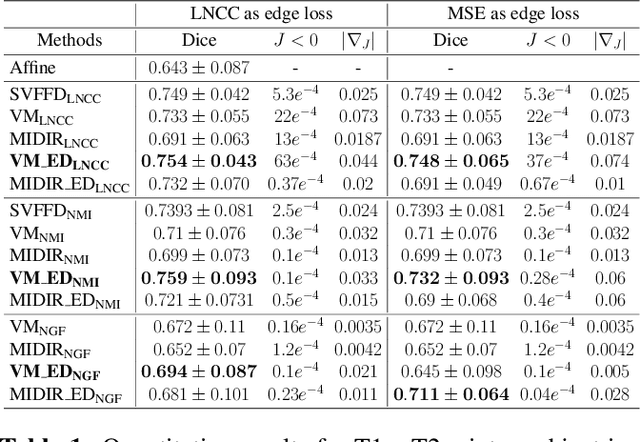


Diffeomorphic deformable multi-modal image registration is a challenging task which aims to bring images acquired by different modalities to the same coordinate space and at the same time to preserve the topology and the invertibility of the transformation. Recent research has focused on leveraging deep learning approaches for this task as these have been shown to achieve competitive registration accuracy while being computationally more efficient than traditional iterative registration methods. In this work, we propose a simple yet effective unsupervised deep learning-based {\em multi-modal} image registration approach that benefits from auxiliary information coming from the gradient magnitude of the image, i.e. the image edges, during the training. The intuition behind this is that image locations with a strong gradient are assumed to denote a transition of tissues, which are locations of high information value able to act as a geometry constraint. The task is similar to using segmentation maps to drive the training, but the edge maps are easier and faster to acquire and do not require annotations. We evaluate our approach in the context of registering multi-modal (T1w to T2w) magnetic resonance (MR) brain images of different subjects using three different loss functions that are said to assist multi-modal registration, showing that in all cases the auxiliary information leads to better results without compromising the runtime.