 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Sarcasm Detection Based on Contrastive Attention Mechanism
Paper and Code
Sep 30, 2021

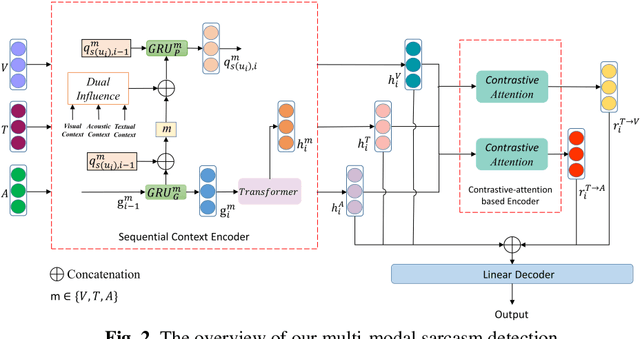
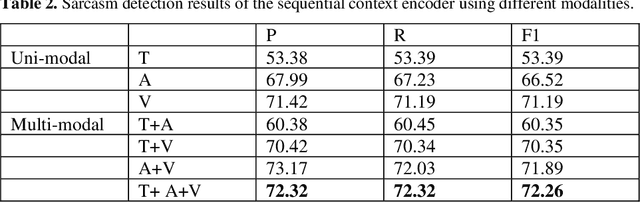
In the past decade, sarcasm detection has been intensively conducted in a textual scenario. With the popularization of video communication, the analysis in multi-modal scenarios has received much attention in recent years. Therefore, multi-modal sarcasm detection, which aims at detecting sarcasm in video conversations, becomes increasingly hot in both the natural language processing community and the multi-modal analysis community. In this paper, considering that sarcasm is often conveyed through incongruity between modalities (e.g., text expressing a compliment while acoustic tone indicating a grumble), we construct a Contras-tive-Attention-based Sarcasm Detection (ConAttSD) model, which uses an inter-modality contrastive attention mechanism to extract several contrastive features for an utterance. A contrastive feature represents the incongruity of information between two modalities. Our experiments on MUStARD, a benchmark multi-modal sarcasm dataset, demonstrate the effectiveness of the proposed ConAttSD model.