 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Cross-Domain Alignment Network for Video Moment Retrieval
Paper and Code
Sep 23, 2022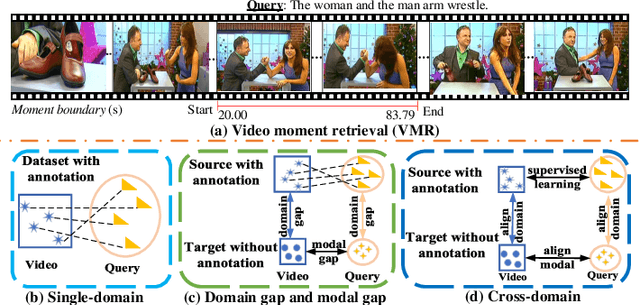
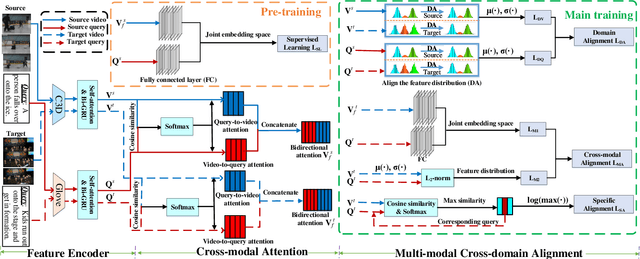
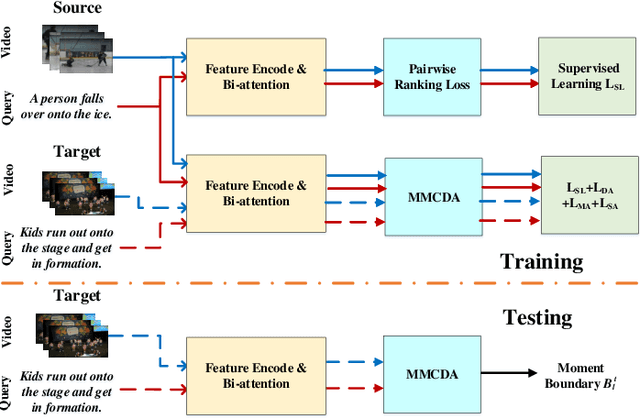
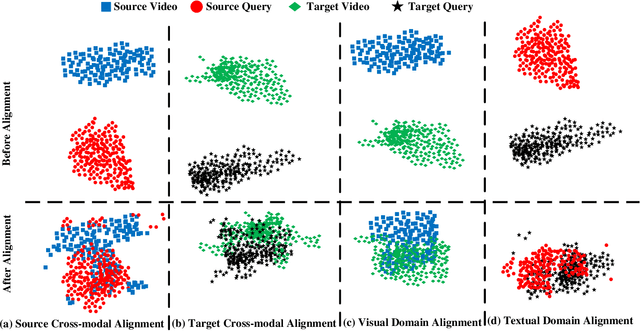
As an increasingly popular task in multimedia information retrieval, video moment retrieval (VMR) aims to localize the target moment from an untrimmed video according to a given language query. Most previous methods depend heavily on numerous manual annotations (i.e., moment boundaries), which are extremely expensive to acquire in practice. In addition, due to the domain gap between different datasets, directly applying these pre-trained models to an unseen domain leads to a significant performance drop. In this paper, we focus on a novel task: cross-domain VMR, where fully-annotated datasets are available in one domain (``source domain''), but the domain of interest (``target domain'') only contains unannotated datasets. As far as we know, we present the first study on cross-domain VMR. To address this new task, we propose a novel Multi-Modal Cross-Domain Alignment (MMCDA) network to transfer the annotation knowledge from the source domain to the target domain. However, due to the domain discrepancy between the source and target domains and the semantic gap between videos and queries, directly applying trained models to the target domain generally leads to a performance drop. To solve this problem, we develop three novel modules: (i) a domain alignment module is designed to align the feature distributions between different domains of each modality; (ii) a cross-modal alignment module aims to map both video and query features into a joint embedding space and to align the feature distributions between different modalities in the target domain; (iii) a specific alignment module tries to obtain the fine-grained similarity between a specific frame and the given query for optimal localization. By jointly training these three modules, our MMCDA can learn domain-invariant and semantic-aligned cross-modal representations.