 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Figurative Language Generation
Paper and Code

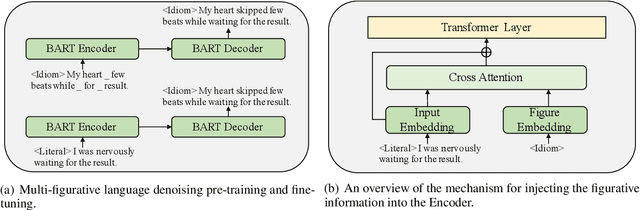

Figurative language generation is the task of reformulating a given text in the desired figure of speech while still being faithful to the original context. We take the first step towards multi-figurative language modelling by providing a benchmark for the automatic generation of five common figurative forms in English. We train mFLAG employing a scheme for multi-figurative language pre-training on top of BART, and a mechanism for injecting the target figurative information into the encoder; this enables the generation of text with the target figurative form from another figurative form without parallel figurative-figurative sentence pairs. Our approach outperforms all strong baselines. We also offer some qualitative analysis and reflections on the relationship between the different figures of speech.