 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Encoder Learning and Stream Fusion for Transformer-Based End-to-End Automatic Speech Recognition
Paper and Code
Mar 31, 2021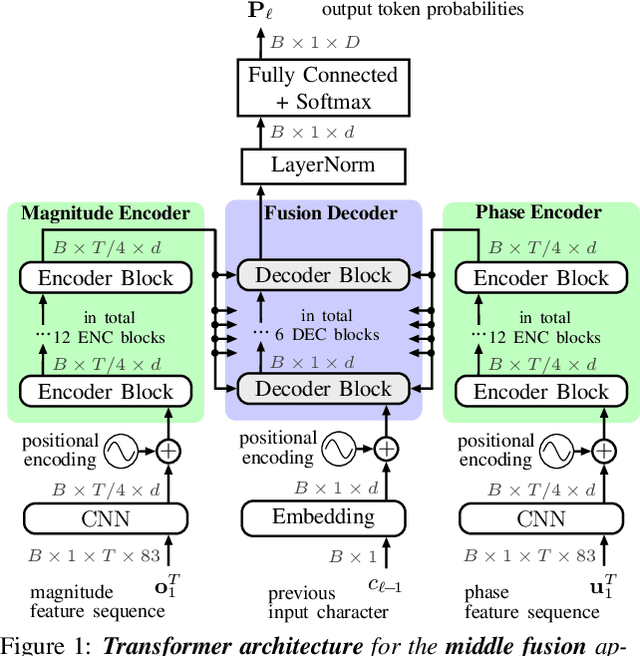
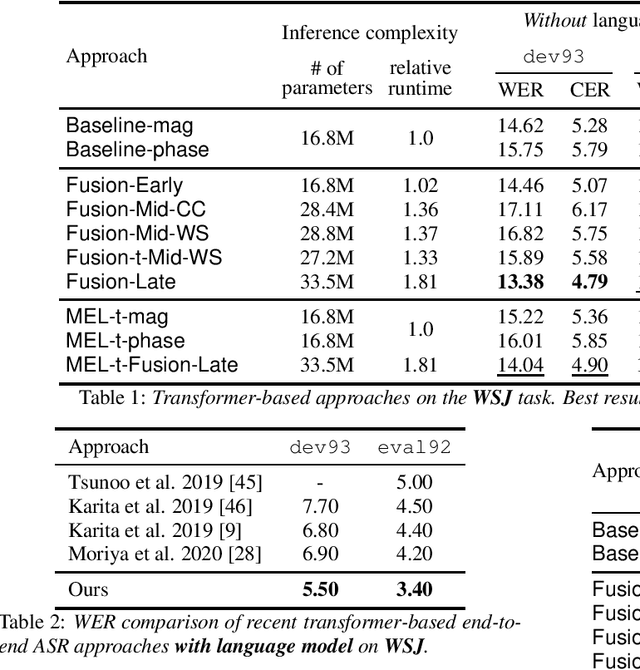
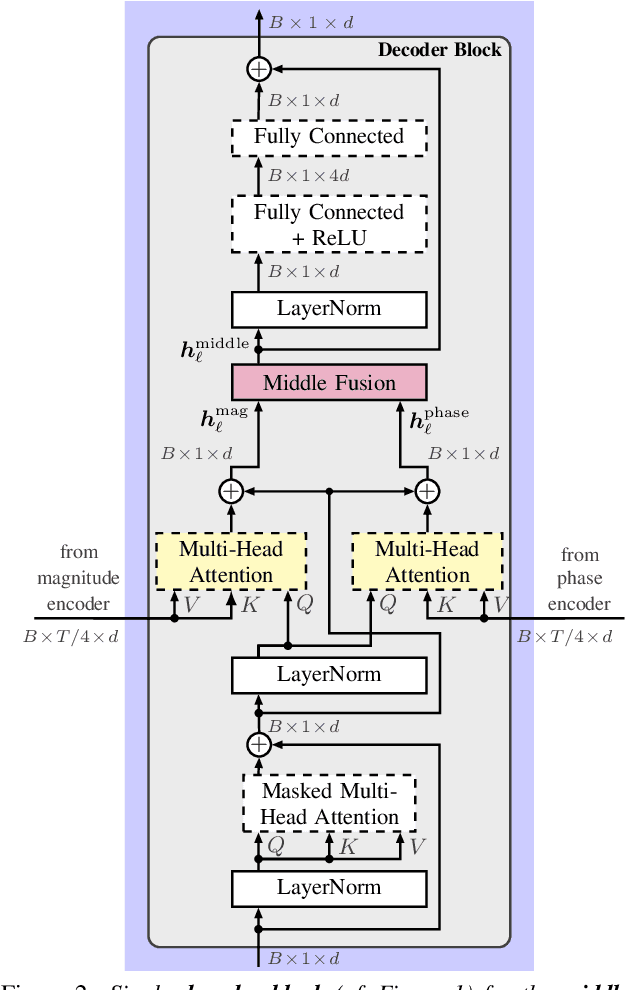
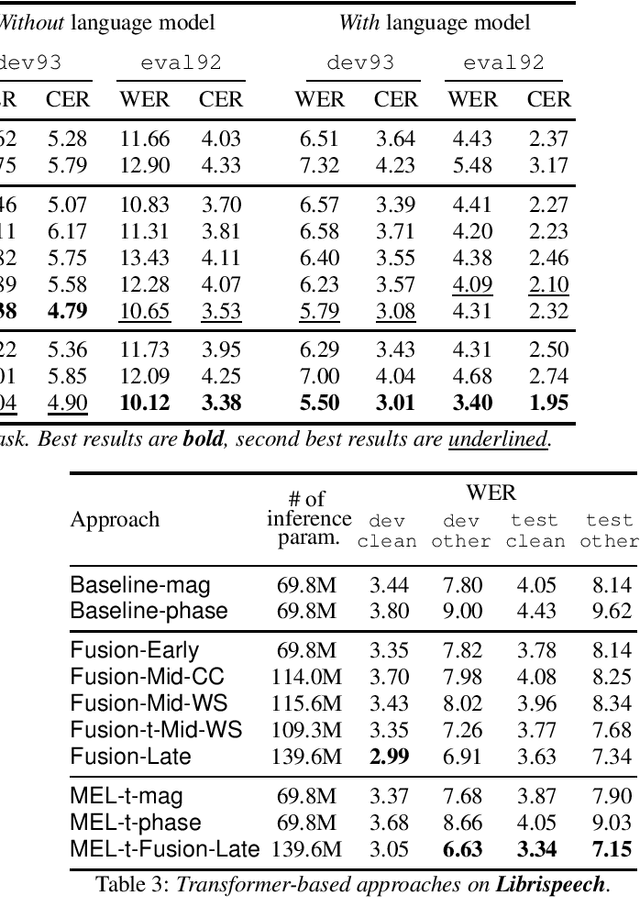
Stream fusion, also known as system combination, is a common technique in automatic speech recognition for traditional hybrid hidden Markov model approaches, yet mostly unexplored for modern deep neural network end-to-end model architectures. Here, we investigate various fusion techniques for the all-attention-based encoder-decoder architecture known as the transformer, striving to achieve optimal fusion by investigating different fusion levels in an example single-microphone setting with fusion of standard magnitude and phase features. We introduce a novel multi-encoder learning method that performs a weighted combination of two encoder-decoder multi-head attention outputs only during training. Employing then only the magnitude feature encoder in inference, we are able to show consistent improvement on Wall Street Journal (WSJ) with language model and on Librispeech, without increase in runtime or parameters. Combining two such multi-encoder trained models by a simple late fusion in inference, we achieve state-of-the-art performance for transformer-based models on WSJ with a significant WER reduction of 19\% relative compared to the current benchmark approach.