 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Channel Multi-Speaker ASR Using 3D Spatial Feature
Paper and Code
Nov 22, 2021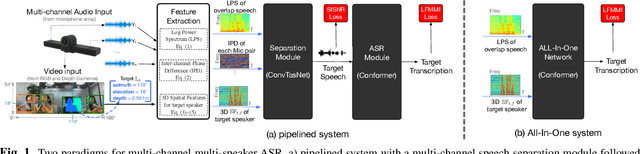

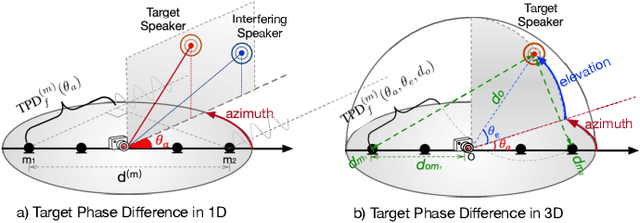
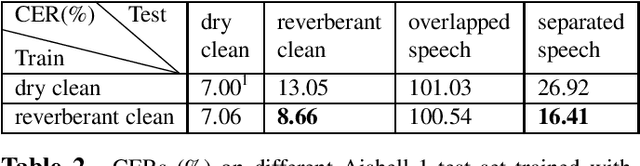
Automatic speech recognition (ASR) of multi-channel multi-speaker overlapped speech remains one of the most challenging tasks to the speech community. In this paper, we look into this challenge by utilizing the location information of target speakers in the 3D space for the first time. To explore the strength of proposed the 3D spatial feature, two paradigms are investigated. 1) a pipelined system with a multi-channel speech separation module followed by the state-of-the-art single-channel ASR module; 2) a "All-In-One" model where the 3D spatial feature is directly used as an input to ASR system without explicit separation modules. Both of them are fully differentiable and can be back-propagated end-to-end. We test them on simulated overlapped speech and real recordings. Experimental results show that 1) the proposed ALL-In-One model achieved a comparable error rate to the pipelined system while reducing the inference time by half; 2) the proposed 3D spatial feature significantly outperformed (31\% CERR) all previous works of using the 1D directional information in both paradigms.