 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Channel Masking with Learnable Filterbank for Sound Source Separation
Paper and Code
Mar 14, 2023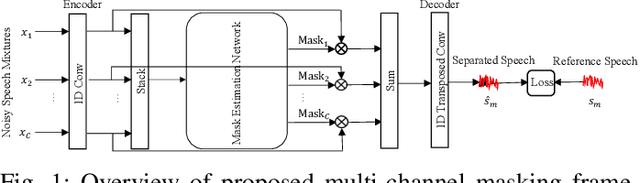
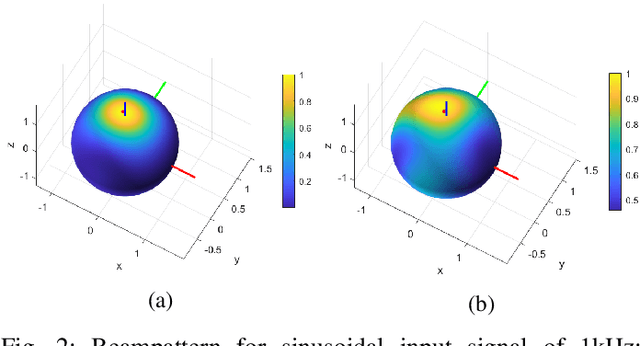
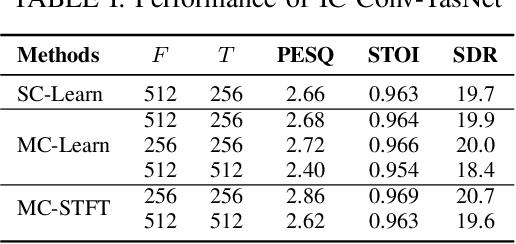
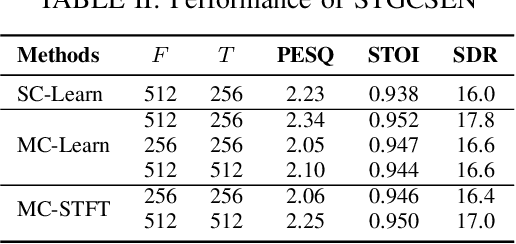
This work proposes a learnable filterbank based on a multi-channel masking framework for multi-channel source separation. The learnable filterbank is a 1D Conv layer, which transforms the raw waveform into a 2D representation. In contrast to the conventional single-channel masking method, we estimate a mask for each individual microphone channel. The estimated masks are then applied to the transformed waveform representation like in the traditional filter-and-sum beamforming operation. Specifically, each mask is used to multiply the corresponding channel's 2D representation, and the masked output of all channels are then summed. At last, a 1D transposed Conv layer is used to convert the summed masked signal into the waveform domain. The experimental results show our method outperforms single-channel masking with a learnable filterbank and can outperform multi-channel complex masking with STFT complex spectrum in the STGCSEN model if a learnable filterbank is transformed to a higher feature dimension. The spatial response analysis also verifies that multi-channel masking in the learnable filterbank domain has spatial selectivity.