 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-channel end-to-end neural network for speech enhancement, source localization, and voice activity detection
Paper and Code
Jun 20, 2022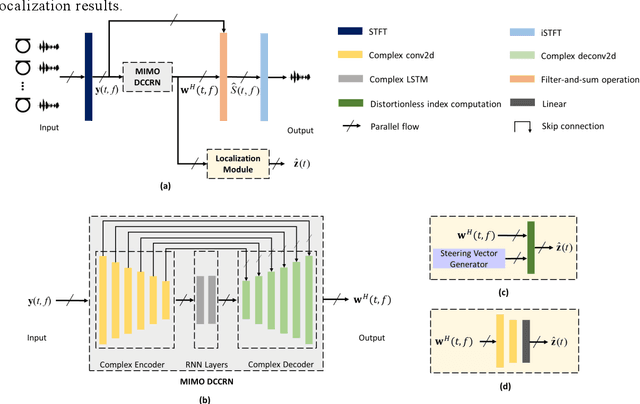
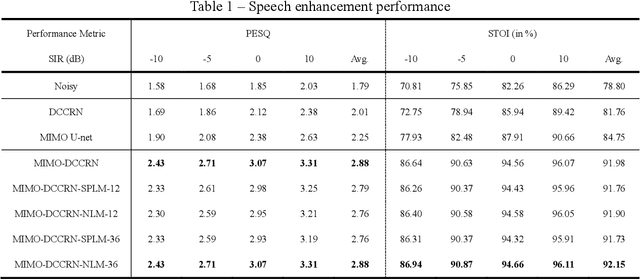
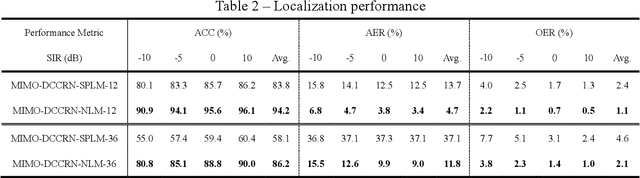
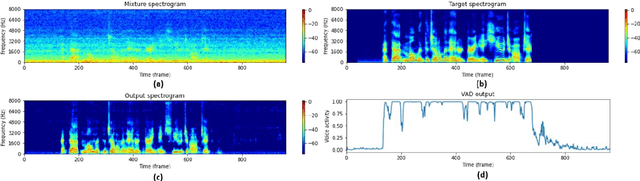
Speech enhancement and source localization has been active research for several decades with a wide range of real-world applications. Recently, the Deep Complex Convolution Recurrent network (DCCRN) has yielded impressive enhancement performance for single-channel systems. In this study, a neural beamformer consisting of a beamformer and a novel multi-channel DCCRN is proposed for speech enhancement and source localization. Complex-valued filters estimated by the multi-channel DCCRN serve as the weights of beamformer. In addition, a one-stage learning-based procedure is employed for speech enhancement and source localization. The proposed network composed of the multi-channel DCCRN and the auxiliary network models the sound field, while minimizing the distortionless response loss function. Simulation results show that the proposed neural beamformer is effective in enhancing speech signals, with speech quality well preserved. The proposed neural beamformer also provides source localization and voice activity detection (VAD) functions.