 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Armed Bandit Strategies for Non-Stationary Reward Distributions and Delayed Feedback Processes
Paper and Code
Feb 22, 2019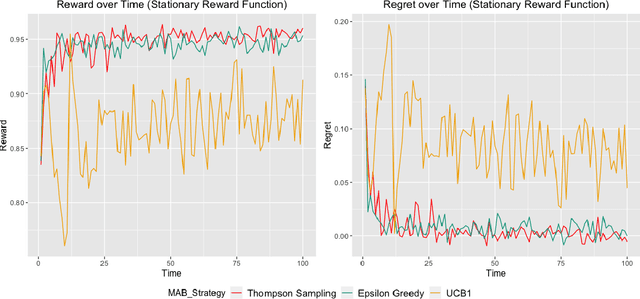

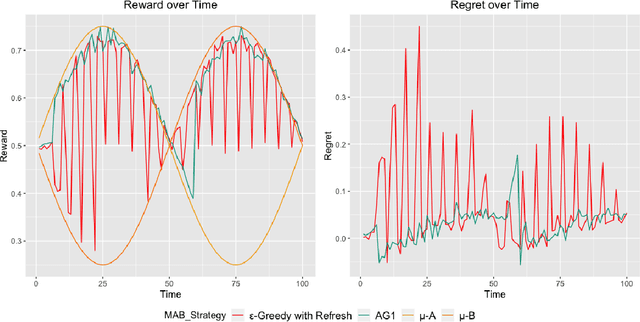
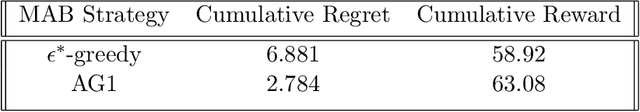
A survey is performed of various Multi-Armed Bandit (MAB) strategies in order to examine their performance in circumstances exhibiting non-stationary stochastic reward functions in conjunction with delayed feedback. We run several MAB simulations to simulate an online eCommerce platform for grocery pick up, optimizing for product availability. In this work, we evaluate several popular MAB strategies, such as $\epsilon$-greedy, UCB1, and Thompson Sampling. We compare the respective performances of each MAB strategy in the context of regret minimization. We run the analysis in the scenario where the reward function is non-stationary. Furthermore, the process experiences delayed feedback, where the reward function is not immediately responsive to the arm played. We devise a new Bayesian technique (BAG1) tailored for non-stationary reward functions in the delayed feedback scenario. The results of the simulation show show superior performance in the context of regret minimization compared to traditional MAB strategies.