 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuddling Labels for Regularization, a novel approach to generalization
Paper and Code
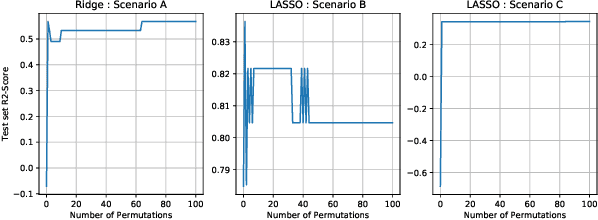
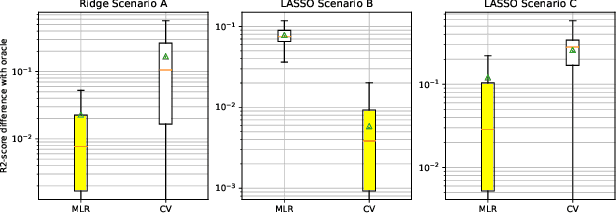
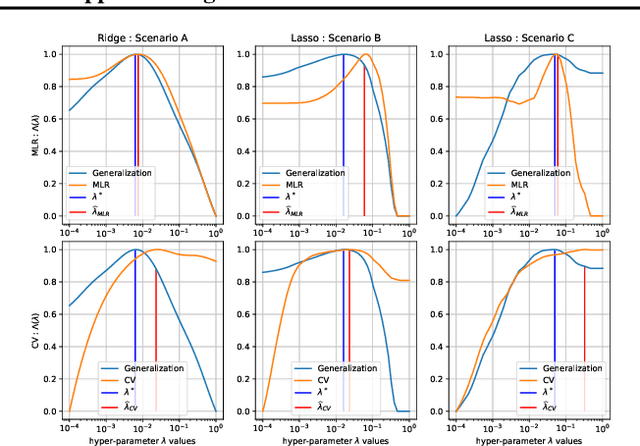
Generalization is a central problem in Machine Learning. Indeed most prediction methods require careful calibration of hyperparameters usually carried out on a hold-out \textit{validation} dataset to achieve generalization. The main goal of this paper is to introduce a novel approach to achieve generalization without any data splitting, which is based on a new risk measure which directly quantifies a model's tendency to overfit. To fully understand the intuition and advantages of this new approach, we illustrate it in the simple linear regression model ($Y=X\beta+\xi$) where we develop a new criterion. We highlight how this criterion is a good proxy for the true generalization risk. Next, we derive different procedures which tackle several structures simultaneously (correlation, sparsity,...). Noticeably, these procedures \textbf{concomitantly} train the model and calibrate the hyperparameters. In addition, these procedures can be implemented via classical gradient descent methods when the criterion is differentiable w.r.t. the hyperparameters. Our numerical experiments reveal that our procedures are computationally feasible and compare favorably to the popular approach (Ridge, LASSO and Elastic-Net combined with grid-search cross-validation) in term of generalization. They also outperform the baseline on two additional tasks: estimation and support recovery of $\beta$. Moreover, our procedures do not require any expertise for the calibration of the initial parameters which remain the same for all the datasets we experimented on.