 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuddling Label Regularization: Deep Learning for Tabular Datasets
Paper and Code
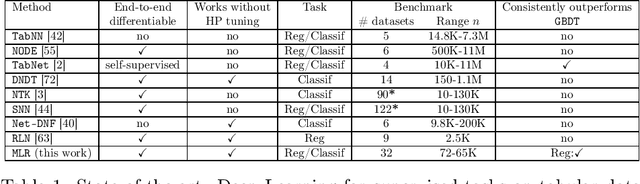


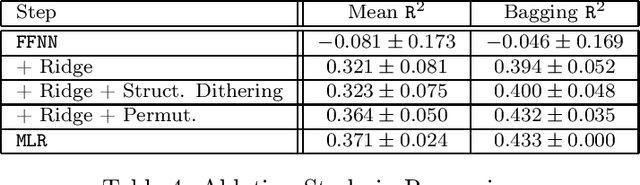
Deep Learning (DL) is considered the state-of-the-art in computer vision, speech recognition and natural language processing. Until recently, it was also widely accepted that DL is irrelevant for learning tasks on tabular data, especially in the small sample regime where ensemble methods are acknowledged as the gold standard. We present a new end-to-end differentiable method to train a standard FFNN. Our method, \textbf{Muddling labels for Regularization} (\texttt{MLR}), penalizes memorization through the generation of uninformative labels and the application of a differentiable close-form regularization scheme on the last hidden layer during training. \texttt{MLR} outperforms classical NN and the gold standard (GBDT, RF) for regression and classification tasks on several datasets from the UCI database and Kaggle covering a large range of sample sizes and feature to sample ratios. Researchers and practitioners can use \texttt{MLR} on its own as an off-the-shelf \DL{} solution or integrate it into the most advanced ML pipelines.