 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-Appearance Interactive Encoding for Object Segmentation in Unconstrained Videos
Paper and Code
Jul 25, 2017
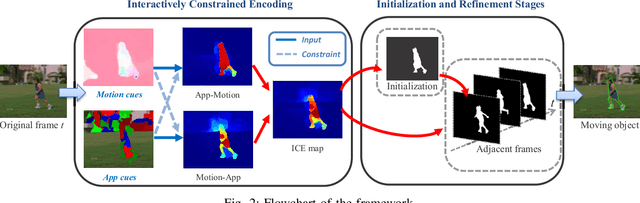


We present a novel method of integrating motion and appearance cues for foreground object segmentation in unconstrained videos. Unlike conventional methods encoding motion and appearance patterns individually, our method puts particular emphasis on their mutual assistance. Specifically, we propose using an interactively constrained encoding (ICE) scheme to incorporate motion and appearance patterns into a graph that leads to a spatiotemporal energy optimization. The reason of utilizing ICE is that both motion and appearance cues for the same target share underlying correlative structure, thus can be exploited in a deeply collaborative manner. We perform ICE not only in the initialization but also in the refinement stage of a two-layer framework for object segmentation. This scheme allows our method to consistently capture structural patterns about object perceptions throughout the whole framework. Our method can be operated on superpixels instead of raw pixels to reduce the number of graph nodes by two orders of magnitude. Moreover, we propose to partially explore the multi-object localization problem with inter-occlusion by weighted bipartite graph matching. Comprehensive experiments on three benchmark datasets (i.e., SegTrack, MOViCS, and GaTech) demonstrate the effectiveness of our approach compared with extensive state-of-the-art methods.