 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotif-guided Time Series Counterfactual Explanations
Paper and Code
Nov 11, 2022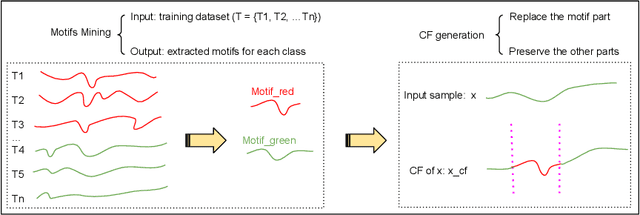
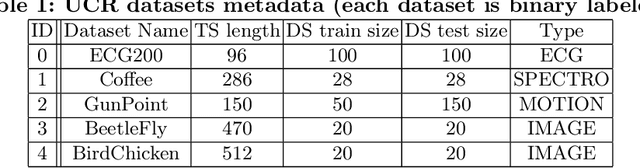
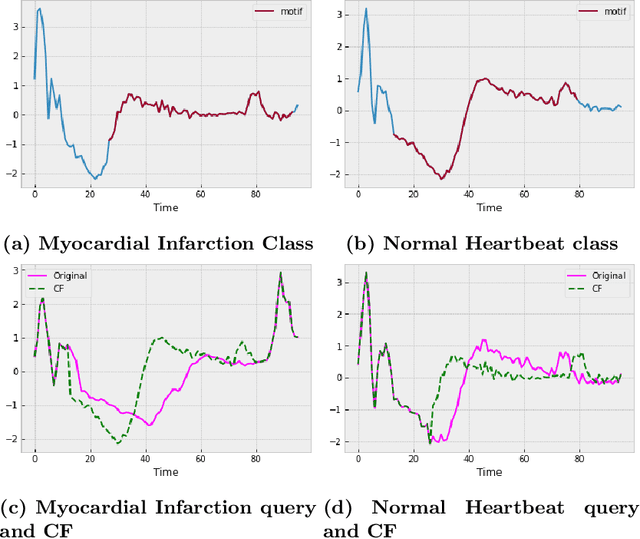
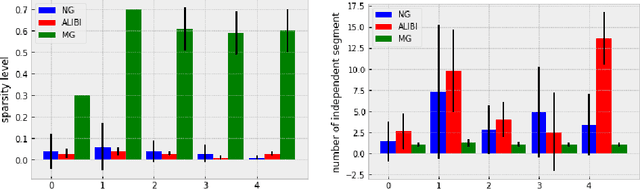
With the rising need of interpretable machine learning methods, there is a necessity for a rise in human effort to provide diverse explanations of the influencing factors of the model decisions. To improve the trust and transparency of AI-based systems, the EXplainable Artificial Intelligence (XAI) field has emerged. The XAI paradigm is bifurcated into two main categories: feature attribution and counterfactual explanation methods. While feature attribution methods are based on explaining the reason behind a model decision, counterfactual explanation methods discover the smallest input changes that will result in a different decision. In this paper, we aim at building trust and transparency in time series models by using motifs to generate counterfactual explanations. We propose Motif-Guided Counterfactual Explanation (MG-CF), a novel model that generates intuitive post-hoc counterfactual explanations that make full use of important motifs to provide interpretive information in decision-making processes. To the best of our knowledge, this is the first effort that leverages motifs to guide the counterfactual explanation generation. We validated our model using five real-world time-series datasets from the UCR repository. Our experimental results show the superiority of MG-CF in balancing all the desirable counterfactual explanations properties in comparison with other competing state-of-the-art baselines.