 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMostly Harmless Machine Learning: Learning Optimal Instruments in Linear IV Models
Paper and Code
Nov 12, 2020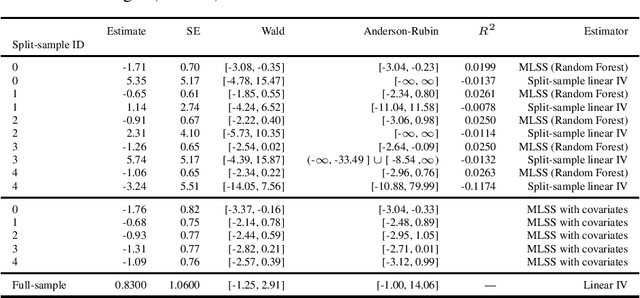
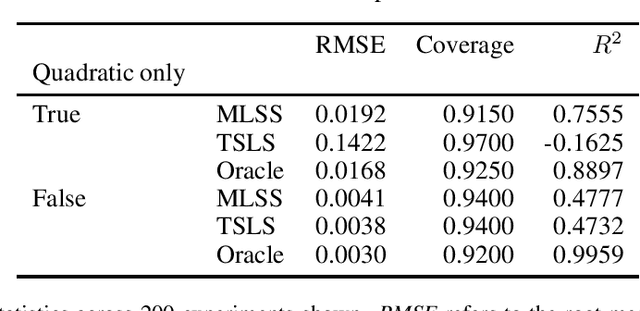
We provide some simple theoretical results that justify incorporating machine learning in a standard linear instrumental variable setting, prevalent in empirical research in economics. Machine learning techniques, combined with sample-splitting, extract nonlinear variation in the instrument that may dramatically improve estimation precision and robustness by boosting instrument strength. The analysis is straightforward in the absence of covariates. The presence of linearly included exogenous covariates complicates identification, as the researcher would like to prevent nonlinearities in the covariates from providing the identifying variation. Our procedure can be effectively adapted to account for this complication, based on an argument by Chamberlain (1992). Our method preserves standard intuitions and interpretations of linear instrumental variable methods and provides a simple, user-friendly upgrade to the applied economics toolbox. We illustrate our method with an example in law and criminal justice, examining the causal effect of appellate court reversals on district court sentencing decisions.