 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphological Tagging and Lemmatization of Albanian: A Manually Annotated Corpus and Neural Models
Paper and Code
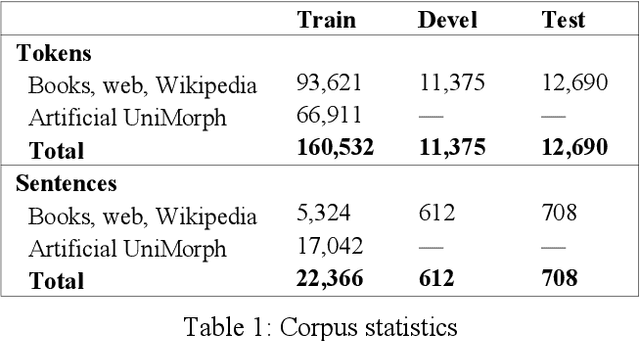
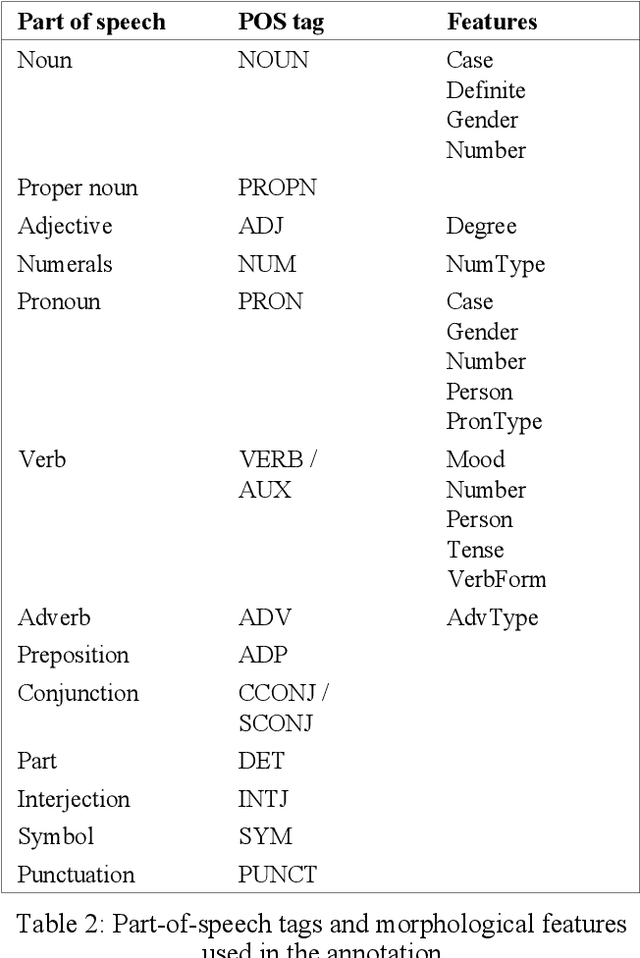

In this paper, we present the first publicly available part-of-speech and morphologically tagged corpus for the Albanian language, as well as a neural morphological tagger and lemmatizer trained on it. There is currently a lack of available NLP resources for Albanian, and its complex grammar and morphology present challenges to their development. We have created an Albanian part-of-speech corpus based on the Universal Dependencies schema for morphological annotation, containing about 118,000 tokens of naturally occuring text collected from different text sources, with an addition of 67,000 tokens of artificially created simple sentences used only in training. On this corpus, we subsequently train and evaluate segmentation, morphological tagging and lemmatization models, using the Turku Neural Parser Pipeline. On the held-out evaluation set, the model achieves 92.74% accuracy on part-of-speech tagging, 85.31% on morphological tagging, and 89.95% on lemmatization. The manually annotated corpus, as well as the trained models are available under an open license.