Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte-Carlo Sampling Approach to Model Selection: A Primer
Paper and Code
Sep 27, 2022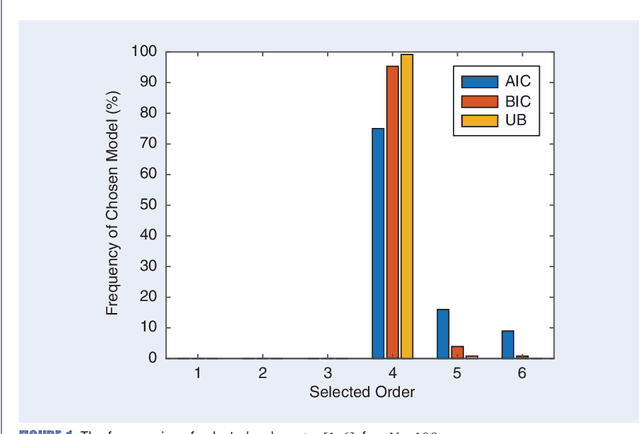
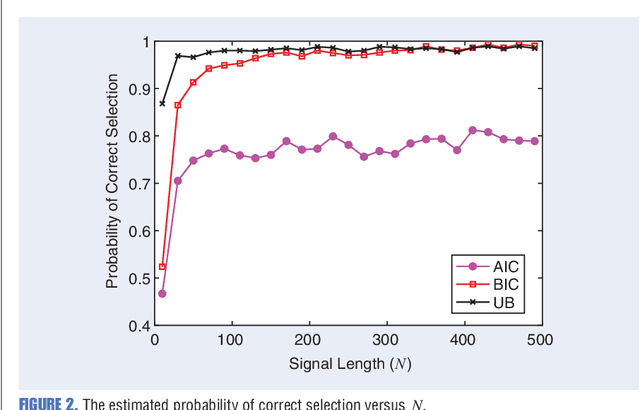
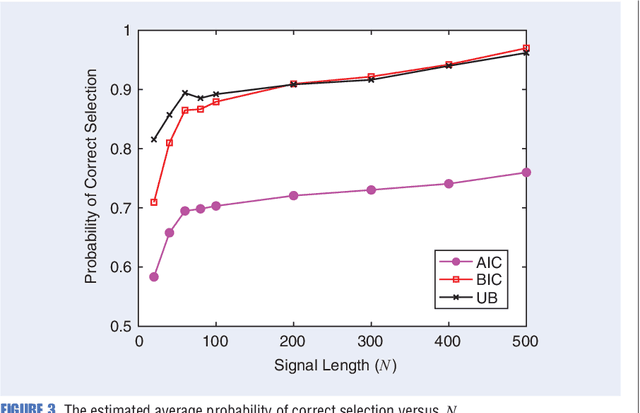
Any data modeling exercise has two main components: parameter estimation and model selection. The latter will be the topic of this lecture note. More concretely we will introduce several Monte-Carlo sampling-based rules for model selection using the maximum a posteriori (MAP) approach. Model selection problems are omnipresent in signal processing applications: examples include selecting the order of an autoregressive predictor, the length of the impulse response of a communication channel, the number of source signals impinging on an array of sensors, the order of a polynomial trend, the number of components of a NMR signal, and so on.
* IEEE Signal Processing Magazine, Vol, 39, no. 5, pp. 85--2, 2022
View paper on