 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte Carlo dropout increases model repeatability
Paper and Code

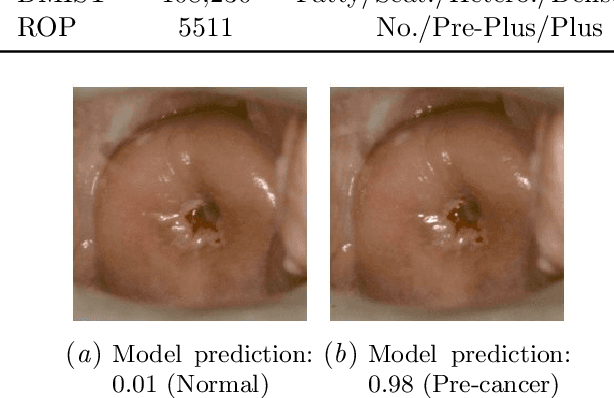
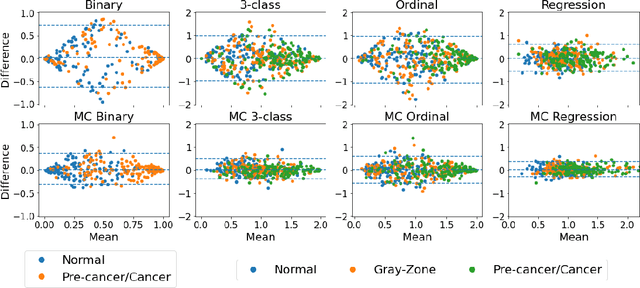
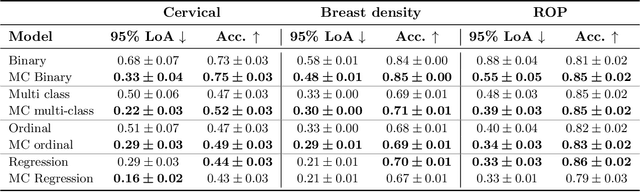
The integration of artificial intelligence into clinical workflows requires reliable and robust models. Among the main features of robustness is repeatability. Much attention is given to classification performance without assessing the model repeatability, leading to the development of models that turn out to be unusable in practice. In this work, we evaluate the repeatability of four model types on images from the same patient that were acquired during the same visit. We study the performance of binary, multi-class, ordinal, and regression models on three medical image analysis tasks: cervical cancer screening, breast density estimation, and retinopathy of prematurity classification. Moreover, we assess the impact of sampling Monte Carlo dropout predictions at test time on classification performance and repeatability. Leveraging Monte Carlo predictions significantly increased repeatability for all tasks on the binary, multi-class, and ordinal models leading to an average reduction of the 95% limits of agreement by 17% points.