 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonotone Retargeting for Unsupervised Rank Aggregation with Object Features
Paper and Code
May 14, 2016
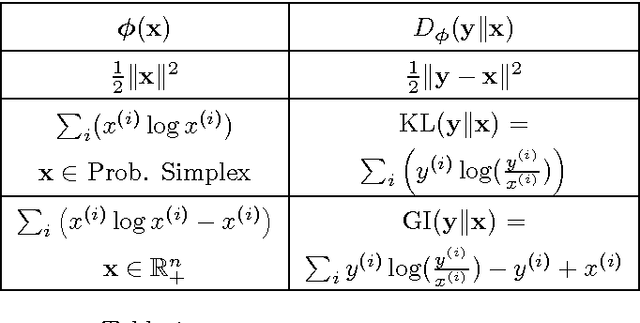
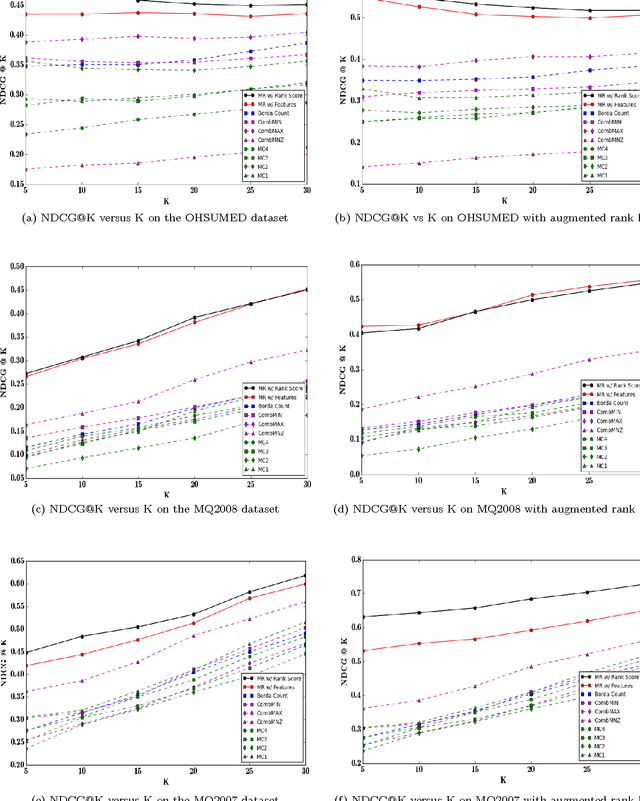
Learning the true ordering between objects by aggregating a set of expert opinion rank order lists is an important and ubiquitous problem in many applications ranging from social choice theory to natural language processing and search aggregation. We study the problem of unsupervised rank aggregation where no ground truth ordering information in available, neither about the true preference ordering between any set of objects nor about the quality of individual rank lists. Aggregating the often inconsistent and poor quality rank lists in such an unsupervised manner is a highly challenging problem, and standard consensus-based methods are often ill-defined, and difficult to solve. In this manuscript we propose a novel framework to bypass these issues by using object attributes to augment the standard rank aggregation framework. We design algorithms that learn joint models on both rank lists and object features to obtain an aggregated rank ordering that is more accurate and robust, and also helps weed out rank lists of dubious validity. We validate our techniques on synthetic datasets where our algorithm is able to estimate the true rank ordering even when the rank lists are corrupted. Experiments on three real datasets, MQ2008, MQ2008 and OHSUMED, show that using object features can result in significant improvement in performance over existing rank aggregation methods that do not use object information. Furthermore, when at least some of the rank lists are of high quality, our methods are able to effectively exploit their high expertise to output an aggregated rank ordering of great accuracy.