 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Depth Parameterizing Networks
Paper and Code

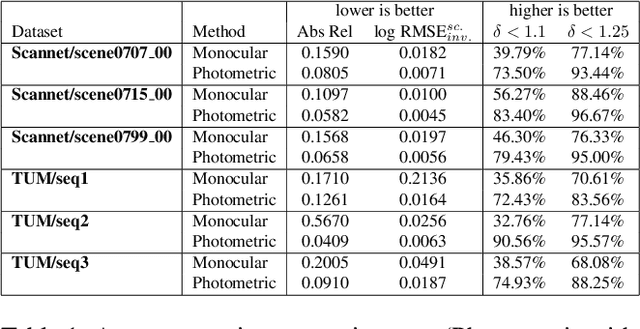
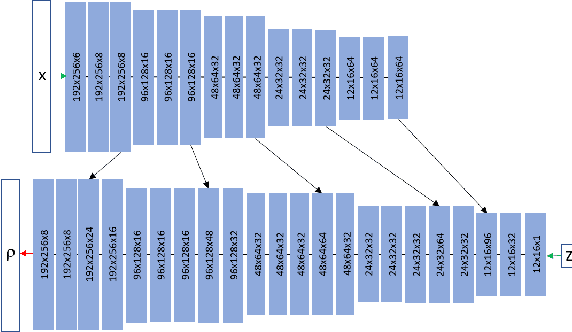
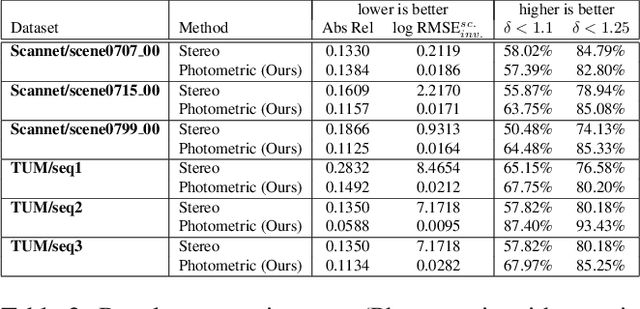
Monocular depth estimation is a highly challenging problem that is often addressed with deep neural networks. While these are able to use recognition of image features to predict reasonably looking depth maps the result often has low metric accuracy. In contrast traditional stereo methods using multiple cameras provide highly accurate estimation when pixel matching is possible. In this work we propose to combine the two approaches leveraging their respective strengths. For this purpose we propose a network structure that given an image provides a parameterization of a set of depth maps with feasible shapes. Optimizing over the parameterization then allows us to search the shapes for a photo consistent solution with respect to other images. This allows us to enforce geometric properties that are difficult to observe in single image as well as relaxes the learning problem allowing us to use relatively small networks. Our experimental evaluation shows that our method generates more accurate depth maps and generalizes better than competing state-of-the-art approaches.