 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONET: Multiview Semi-supervised Keypoint via Epipolar Divergence
Paper and Code


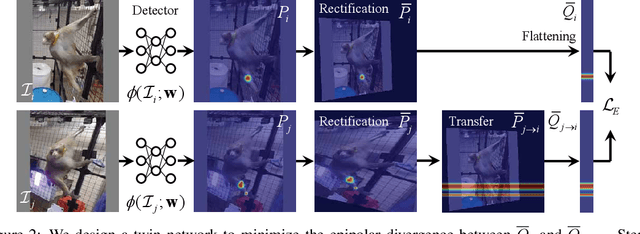
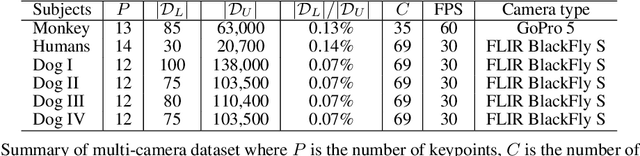
This paper presents MONET---an end-to-end semi-supervised learning framework for a pose detector using multiview image streams. What differentiates MONET from existing models is its capability of detecting general subjects including non-human species without a pre-trained model. A key challenge of such subjects lies in the limited availability of expert manual annotations, which often leads to a large bias in the detection model. We address this challenge by using the epipolar constraint embedded in the unlabeled data in two ways. First, given a set of the labeled data, the keypoint trajectories can be reliably reconstructed in 3D using multiview optical flows, resulting in considerable data augmentation in space and time from nearly exhaustive views. Second, the detection across views must geometrically agree with each other. We introduce a new measure of geometric consistency in keypoint distributions called epipolar divergence---a generalized distance from the epipolar lines to the corresponding keypoint distribution. Epipolar divergence characterizes when two view keypoint distributions produces zero reprojection error. We design a twin network that minimizes the epipolar divergence through stereo rectification that can significantly alleviate computational complexity and sampling aliasing in training. We demonstrate that our framework can localize customized keypoints of diverse species, e.g., humans, dogs, and monkeys.