Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomentum in Reinforcement Learning
Paper and Code
Oct 21, 2019
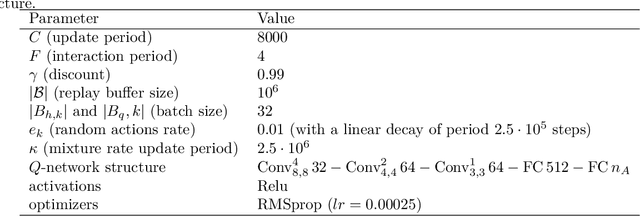


We adapt the optimization's concept of momentum to reinforcement learning. Seeing the state-action value functions as an analog to the gradients in optimization, we interpret momentum as an average of consecutive $q$-functions. We derive Momentum Value Iteration (MoVI), a variation of Value Iteration that incorporates this momentum idea. Our analysis shows that this allows MoVI to average errors over successive iterations. We show that the proposed approach can be readily extended to deep learning. Specifically, we propose a simple improvement on DQN based on MoVI, and experiment it on Atari games.
View paper on