 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolecular Fingerprints Are Strong Models for Peptide Function Prediction
Paper and Code

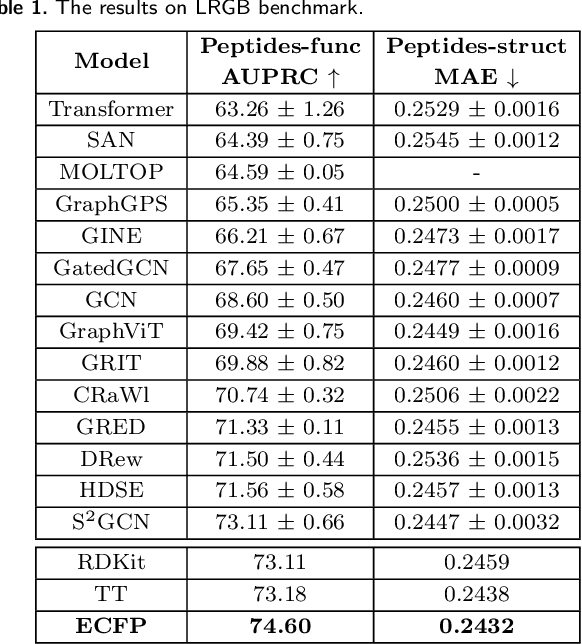

We study the effectiveness of molecular fingerprints for peptide property prediction and demonstrate that domain-specific feature extraction from molecular graphs can outperform complex and computationally expensive models such as GNNs, pretrained sequence-based transformers and multimodal ensembles, even without hyperparameter tuning. To this end, we perform a thorough evaluation on 126 datasets, achieving state-of-the-art results on LRGB and 5 other peptide function prediction benchmarks. We show that models based on count variants of ECFP, Topological Torsion, and RDKit molecular fingerprints and LightGBM as classification head are remarkably robust. The strong performance of molecular fingerprints, which are intrinsically very short-range feature encoders, challenges the presumed importance of long-range interactions in peptides. Our conclusion is that the use of molecular fingerprints for larger molecules, such as peptides, can be a computationally feasible, low-parameter, and versatile alternative to sophisticated deep learning models.