 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling Lexical Ambiguity with Density Matrices
Paper and Code
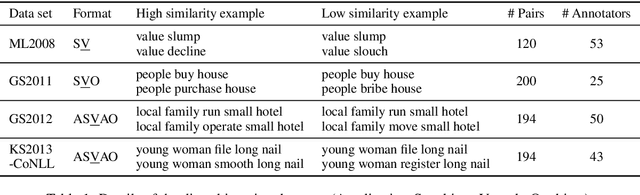
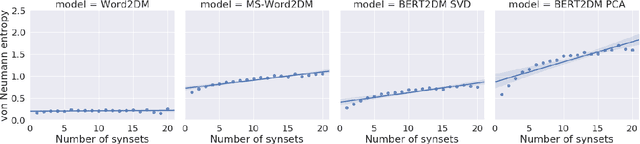
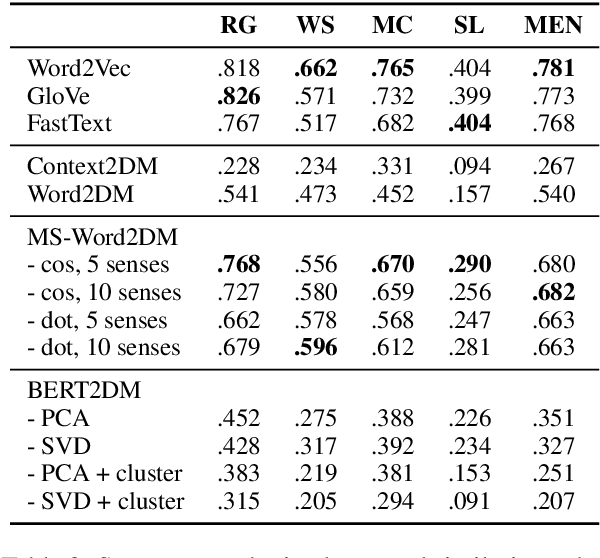
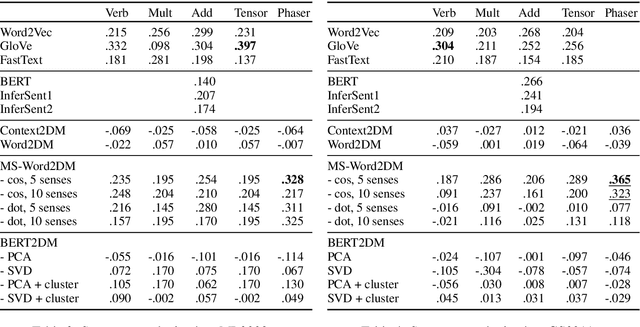
Words can have multiple senses. Compositional distributional models of meaning have been argued to deal well with finer shades of meaning variation known as polysemy, but are not so well equipped to handle word senses that are etymologically unrelated, or homonymy. Moving from vectors to density matrices allows us to encode a probability distribution over different senses of a word, and can also be accommodated within a compositional distributional model of meaning. In this paper we present three new neural models for learning density matrices from a corpus, and test their ability to discriminate between word senses on a range of compositional datasets. When paired with a particular composition method, our best model outperforms existing vector-based compositional models as well as strong sentence encoders.