 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling and Correcting Bias in Sequential Evaluation
Paper and Code
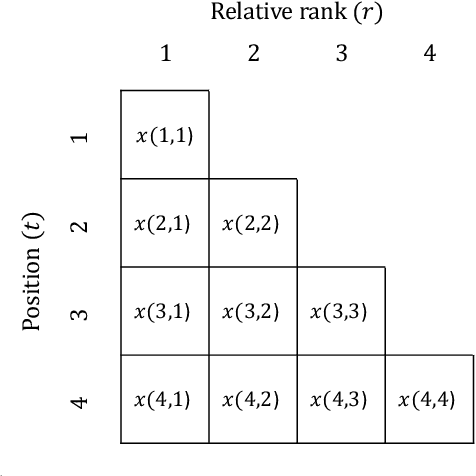
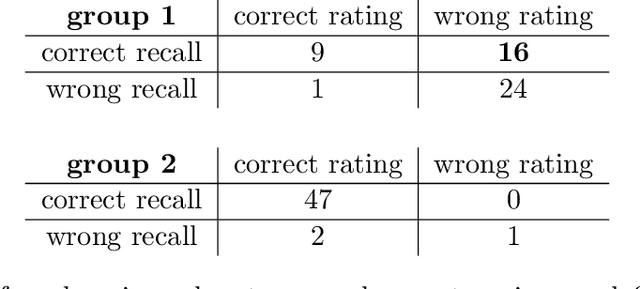
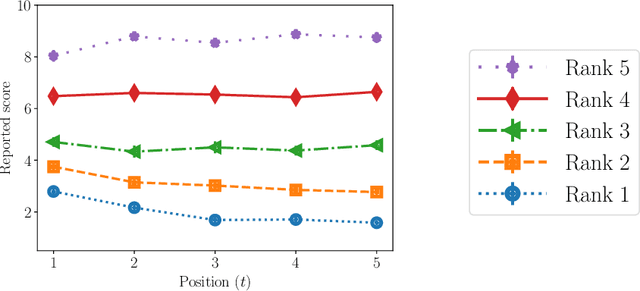
We consider the problem of sequential evaluation, in which an evaluator observes candidates in a sequence and assigns scores to these candidates in an online, irrevocable fashion. Motivated by the psychology literature that has studied sequential bias in such settings -- namely, dependencies between the evaluation outcome and the order in which the candidates appear -- we propose a natural model for the evaluator's rating process that captures the lack of calibration inherent to such a task. We conduct crowdsourcing experiments to demonstrate various facets of our model. We then proceed to study how to correct sequential bias under our model by posing this as a statistical inference problem. We propose a near-linear time, online algorithm for this task and prove guarantees in terms of two canonical ranking metrics, matched with lower bounds demonstrating optimality in a certain sense. Our algorithm outperforms the de facto method of using the rankings induced by the reported scores.