 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Predictive Control via Cross-Entropy and Gradient-Based Optimization
Paper and Code
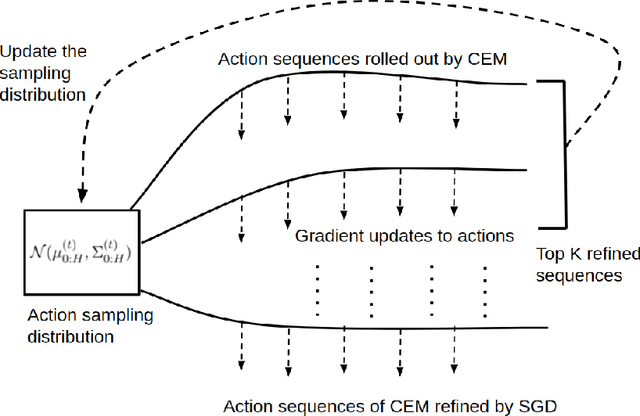

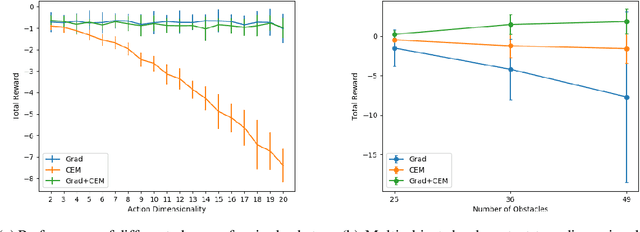
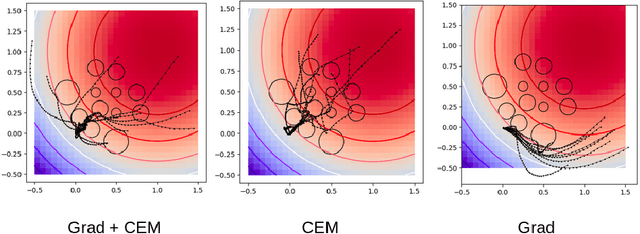
Recent works in high-dimensional model-predictive control and model-based reinforcement learning with learned dynamics and reward models have resorted to population-based optimization methods, such as the Cross-Entropy Method (CEM), for planning a sequence of actions. To decide on an action to take, CEM conducts a search for the action sequence with the highest return according to the dynamics model and reward. Action sequences are typically randomly sampled from an unconditional Gaussian distribution and evaluated on the environment. This distribution is iteratively updated towards action sequences with higher returns. However, this planning method can be very inefficient, especially for high-dimensional action spaces. An alternative line of approaches optimize action sequences directly via gradient descent, but are prone to local optima. We propose a method to solve this planning problem by interleaving CEM and gradient descent steps in optimizing the action sequence. Our experiments show faster convergence of the proposed hybrid approach, even for high-dimensional action spaces, avoidance of local minima, and better or equal performance to CEM. Code accompanying the paper is available here https://github.com/homangab/gradcem.