 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel interpretation using improved local regression with variable importance
Paper and Code
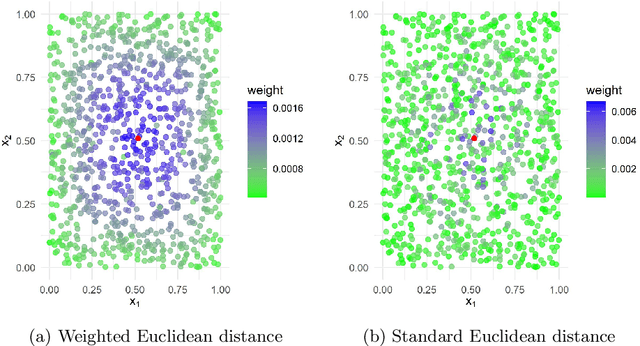

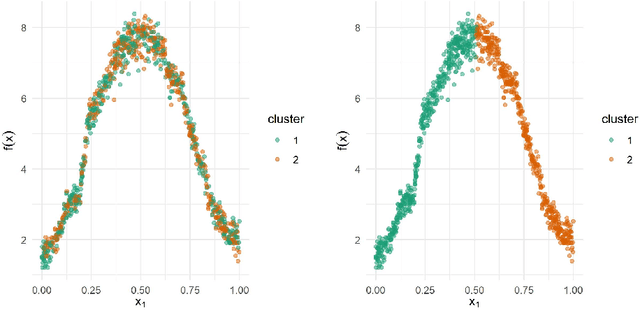
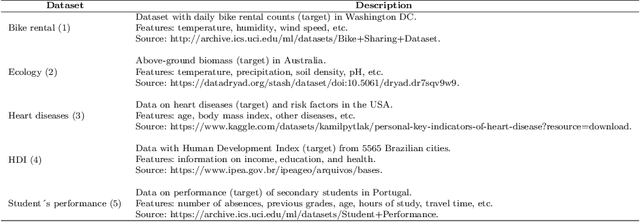
A fundamental question on the use of ML models concerns the explanation of their predictions for increasing transparency in decision-making. Although several interpretability methods have emerged, some gaps regarding the reliability of their explanations have been identified. For instance, most methods are unstable (meaning that they give very different explanations with small changes in the data), and do not cope well with irrelevant features (that is, features not related to the label). This article introduces two new interpretability methods, namely VarImp and SupClus, that overcome these issues by using local regressions fits with a weighted distance that takes into account variable importance. Whereas VarImp generates explanations for each instance and can be applied to datasets with more complex relationships, SupClus interprets clusters of instances with similar explanations and can be applied to simpler datasets where clusters can be found. We compare our methods with state-of-the art approaches and show that it yields better explanations according to several metrics, particularly in high-dimensional problems with irrelevant features, as well as when the relationship between features and target is non-linear.