 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Free Characterizations of the Hamilton-Jacobi-Bellman Equation and Convex Q-Learning in Continuous Time
Paper and Code
Oct 14, 2022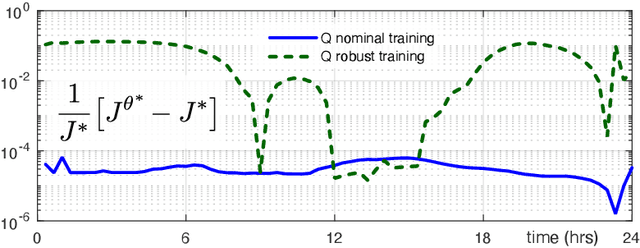
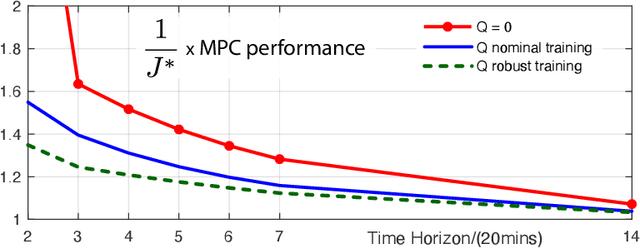

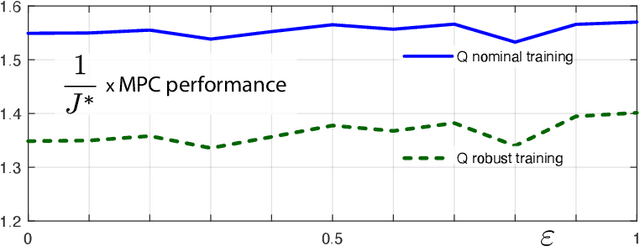
Convex Q-learning is a recent approach to reinforcement learning, motivated by the possibility of a firmer theory for convergence, and the possibility of making use of greater a priori knowledge regarding policy or value function structure. This paper explores algorithm design in the continuous time domain, with finite-horizon optimal control objective. The main contributions are (i) Algorithm design is based on a new Q-ODE, which defines the model-free characterization of the Hamilton-Jacobi-Bellman equation. (ii) The Q-ODE motivates a new formulation of Convex Q-learning that avoids the approximations appearing in prior work. The Bellman error used in the algorithm is defined by filtered measurements, which is beneficial in the presence of measurement noise. (iii) A characterization of boundedness of the constraint region is obtained through a non-trivial extension of recent results from the discrete time setting. (iv) The theory is illustrated in application to resource allocation for distributed energy resources, for which the theory is ideally suited.