 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Free Algorithm and Regret Analysis for MDPs with Peak Constraints
Paper and Code
Mar 11, 2020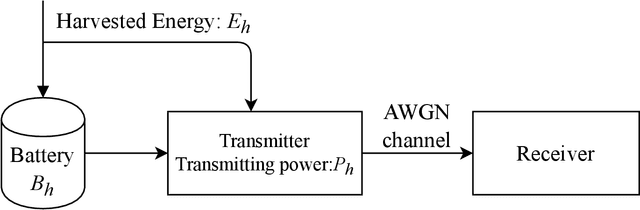


In the optimization of dynamic systems, the variables typically have constraints. Such problems can be modeled as a constrained Markov Decision Process (MDP). This paper considers a model-free approach to the problem, where the transition probabilities are not known. In the presence of peak constraints, the agent has to choose the policy to maximize the long-term average reward as well as satisfy the constraints at each time. We propose modifications to the standard Q-learning problem for unconstrained optimization to come up with an algorithm with peak constraints. The proposed algorithm is shown to achieve $O(T^{1/2+\gamma})$ regret bound for the obtained reward, and $O(T^{1-\gamma})$ regret bound for the constraint violation for any $\gamma \in(0,1/2)$ and time-horizon $T$. We note that these are the first results on regret analysis for constrained MDP, where the transition problems are not known apriori. We demonstrate the proposed algorithm on an energy harvesting problem where it outperforms state-of-the-art and performs close to the theoretical upper bound of the studied optimization problem.