 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-based Offline Imitation Learning with Non-expert Data
Paper and Code
Jun 11, 2022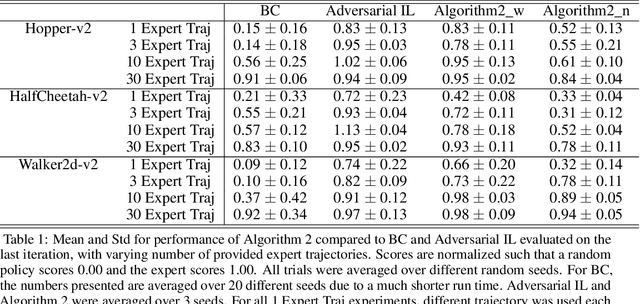


Although Behavioral Cloning (BC) in theory suffers compounding errors, its scalability and simplicity still makes it an attractive imitation learning algorithm. In contrast, imitation approaches with adversarial training typically does not share the same problem, but necessitates interactions with the environment. Meanwhile, most imitation learning methods only utilises optimal datasets, which could be significantly more expensive to obtain than its suboptimal counterpart. A question that arises is, can we utilise the suboptimal dataset in a principled manner, which otherwise would have been idle? We propose a scalable model-based offline imitation learning algorithmic framework that leverages datasets collected by both suboptimal and optimal policies, and show that its worst case suboptimality becomes linear in the time horizon with respect to the expert samples. We empirically validate our theoretical results and show that the proposed method \textit{always} outperforms BC in the low data regime on simulated continuous control domains